Increasingly, agricultural scientists in Asia and Africa are using the gene-editing tool CRISPR to develop disease-resistant, high-yield crop varieties. Many, especially those in government research laboratories, are underestimating the importance of the patent and licensing rules that surround tools such as CRISPR.
The holders of patents on the CRISPR–Cas9 system have rights over discoveries made with it, because their invention makes those discoveries possible. Indian researchers have been able to use CRISPR–Cas9 legally since 2022, when the Indian Patent Office granted a local patent on the tool to the Dublin-based company ERS Genomics. ERS sets the rules of the tool’s use. As a result, scientists can use CRISPR for academic purposes, but cannot commercialize any resulting scientific breakthroughs.
CRISPR cures and cancer vaccines: researchers can help to shepherd them to market
In agriculture, that’s a problem. I made a similar mistake when starting my career in 1997. As a biotechnologist at the Indian Council of Agricultural Research (ICAR), I was assigned as one of the principal investigators of the project to develop genetically modified, pest-resistant Bt cotton.
Producing transgenic crops such as Bt cotton involves incorporating foreign DNA — in this case, genes from the bacterium Bacillus thuringiensis (hence ‘Bt’) — into a crop’s genome to induce desired traits. Indian scientists published a lot of research on transgenic crops in the 2000s, but the patent on the relevant Bt gene was held by the agrochemical company Monsanto (now owned by Bayer in Leverkusen, Germany), which did not allow commercial use of the research results. Ultimately, Indian farmers could not reap the benefits of state-subsidized seed varieties; those using Bt cotton now rely on expensive proprietary seeds.
Having witnessed one failed project, I urge scientists in low- and middle-income countries to pay more attention to who owns CRISPR–Cas9 patents and under what terms they are willing to license this innovation.
‘ChatGPT for CRISPR’ creates new gene-editing tools
For instance, India’s ministry of agriculture has launched a 5-billion-rupee (US$60-million) initiative to expand genome-editing research to develop climate-resilient and bio-fortified seed varieties. Scientists in India who rely on patented toolkits to ramp up their research output will be wasting their time if those seeds cannot be sold.
India already has fewer CRISPR patents than countries such as China and the United States. Acquiring commercial licences for full use of patent-protected CRISPR toolkits can be expensive. For example, in 2023, Vertex Pharmaceuticals in Boston, Massachusetts, secured approval to sell its CRISPR-based treatment for sickle-cell disease only after paying $50 million up front in fees to a licence-holder authorized by the Broad Institute, a genomic-research centre in Cambridge, Massachusetts, that holds the patents.
Indian researchers could turn to freely available CRISPR toolkits offered by non-profit repositories such as AddGene in Watertown, Massachusetts. But these, too, can be used only for research, and not for commercial purposes. Another option is to negotiate licences for a patent pool, which would allow access to multiple patents at once.
A ‘one nation, one licence’ policy for CRISPR toolkits could allow Indian researchers and institutions to access gene-editing technologies under a single government-negotiated agreement, reducing costs and simplifying access. It would be similar to the ‘one nation, one subscription’ initiative, launched last month, which provides researchers across India with universal access to scientific journals. ICAR’s public–private partnership programmes could be leveraged to raise the necessary funds.
EU proposal on CRISPR-edited crops is welcome — but not enough
The best way forward, however, is to do the grunt work and develop home-grown CRISPR toolkits, as China seems to be doing. Until now, components of the kits, such as the protein Cas9, have been discovered mainly by studying microorganisms, which use molecular scissors to detect and destroy the DNA of invading viruses. India’s vast microbial biodiversity and its expertise in artificial intelligence, which can be used to analyse genetic data and predict viable proteins, could catalyse the discovery of molecular pathways by a different route.
Already, the prohibitive cost of commercially available CRISPR-based gene therapy for sickle-cell disease — up to $3 million per recipient — has prompted researchers at India’s Institute of Genomics and Integrative Biology in Delhi to develop low-cost, locally made CRISPR tools to make such treatments more affordable. Agricultural scientists need to do something similar.
Indian funding agencies should review proposed projects to genetically modify seeds, to ensure that they address intellectual-property concerns and have clear commercial applications. This would help to align funding with projects that can have real-world impact and economic value for farmers. Agricultural scientists in low-income countries also need adequate training in the business and economic principles of modern biotechnology research.
Farmers in India want to grow climate-resilient rice or sweet pink pineapples, which could be developed with the aid of CRISPR. Under current standards, these crops face fewer regulatory hurdles for field trials than do transgenic varieties, making their adoption easier. To improve the economic well-being and food security of millions of people, agricultural scientists must devise ways to navigate the intellectual-property thicket and develop products that can be commercialized.
DNA fragments extracted from archaeological human remains can be sequenced to identify the microorganisms that caused disease.Credit: Microgen/Getty
Over the past ten years or so, investigations of degraded or ‘ancient’ DNA have skyrocketed. By extracting DNA fragments from diverse sources —from human teeth and faeces to soil samples and ice cores — researchers have uncovered the stories of all sorts of organisms and ecosystems stretching back for millennia.
Investigators have used ancient genomics to discover the previously unknown Denisovan hominin, an evolutionary cousin and contemporary of Neanderthals that left hardly any fossil record; to identify which microorganisms caused human disease thousands of years ago; and to establish the geographical origins of domesticated plants and animals, including maize (corn) and horses1. Ancient genomics has also been used to reconstruct the composition of Pleistocene ecosystems that existed up to two million years ago2; and even to identify the wearers of ice-age jewellery3.
Most DNA sequence data are now archived in dedicated, publicly accessible databases, and the ancient DNA field has been heralded by some as a poster child for best practices in genetic data sharing4,5. However, as the pace of ancient DNA research has increased — largely thanks to the latest capabilities in DNA sequencing (see ‘A sampling surge’) — so, too, have problems with data archiving.
Often, only some of the data obtained in any one study are uploaded to publicly available databases. Furthermore, the associated metadata — information on the age of the sample, where it was found, how the DNA was extracted and chemically treated, and so on — are frequently inaccurate or incomplete.
Here, we set out the nature of these problems and outline steps to overcome them, so that this astonishing record of the genetic past can be digitally preserved and used again and again.
Data loss
Ancient genomic data have been obtained from more than 10,000 humans6, some 700 microbes and viruses7 and, by our estimate, more than 2,000 plant and non-human animal samples. At least 2,200 ancient host-associated and environmental microbiomes (communities of microorganisms) have been sequenced7 (see also go.nature.com/3bcaxtv).
One major problem, however, is that not all sequences end up being archived.
Earlier this year, one of us (A.B.) assessed what data and metadata had been uploaded into publicly accessible databases by the authors of 42 studies of ancient DNA. All studies involved the analysis of ancient DNA extracted from humans or non-human animals, and had been published in 2021, 2022 or 2023 in the journals Nature, Science and Cell. In about half of the papers, researchers archived only those sequences that they had managed to align to a reference genome, such as that for ancient human remains, leaving no record of the unaligned sequences (see ‘A snapshot of data-archiving troubles’). This represents a permanent loss of data for more than 3,000 ancient samples analysed in just these studies8.
Source: Ref. 8
It might seem that any sequence that does not align to the reference genome is irrelevant. But improvements in computational methods and more-complete reference genomes could enable researchers to align such sequences in the future. Also, even if some of the unaligned sequences are not from the species of interest, this does not mean that they have no scientific value. On the contrary, these sequences could be among the most interesting in the data set, especially if they originated from pathogenic microbes that infected the host.
First DNA from Pompeii body casts illuminates who victims were
The study of ancient microbes has become a field in its own right, and is transforming our understanding of microbial evolution and the history of many infectious diseases. Until 2015, for instance, archaeologists and historians thought that plague (caused by the bacterium Yersinia pestis) emerged as a significant human disease only around 1,500 years ago. Analyses of non-aligned sequences from Neolithic and Bronze Age human remains have revealed, however, that outbreaks of the plague were occurring 5,000 years ago9. Researchers have likewise used studies of non-aligned sequences extracted from human remains to illuminate the evolutionary history of infectious agents such as smallpox, hepatitis B virus and parvovirus during the past 10,000 years10. Such work could help scientists to improve their understanding of current infectious-disease threats.
Another problematic archiving practice is the uploading of digitally trimmed sequences. In their analyses, researchers sometimes remove the last few nucleotides from DNA fragments (usually the most degraded parts of the molecule) to increase the likelihood that the fragments will align to a reference genome. Just as with the exclusion of non-aligned sequences, uploading only these trimmed sequences to public databases limits future researchers’ abilities to replicate findings and to authenticate that the data carry the expected patterns of degradation. It leads to the permanent loss of potentially useful data from the scientific record.
To further complicate efforts to reuse data, some researchers upload merged data that have been collected at different times and obtained using various laboratory protocols. We have also found that data sets obtained from different samples are sometimes incorrectly reported as coming from the same sample, and that data sets from a single sample are sometimes incorrectly registered to multiple samples8,11.
Metadata mess
Being able to reuse ancient DNA data easily and efficiently doesn’t just require researchers to make all their primary data available — it also requires them to annotate those data accurately and comprehensively.
At a minimum, information is needed on the estimated age of the remains being studied, where in the world those remains were found, the type of tissue or material sampled, and key technical details, such as whether the ancient DNA was chemically treated to repair or remove the post-mortem damage that accumulates in such molecules1.
By analysing ancient DNA, researchers are uncovering the stories of extinct organisms, such as the woolly mammoth (Mammuthus primigenius; artist’s impression).Credit: Daniel Eskridge/Getty
Public data archives, such as the European Nucleotide Archive (ENA), provide systems for reporting some of this information. But they are underused by the ancient DNA community. In A.B.’s survey of 42 studies, researchers submitting data to archives included information on the geographical origins of samples in only about 60% of studies, and on the age of the sample in only about 17% of studies8.
Part of the problem is that the systems for recording metadata in standard archives are not designed with ancient DNA in mind. It is often unclear how researchers should record information on when an organism lived, for example, or how to indicate that only imprecise age and geographical information is available. Also, researchers often have different understandings about what information should be recorded. Does ‘geographical location’ mean the place of excavation or the museum from where the remains were sampled? For excavation sites, should the name of the nearest town be provided or the latitude and longitude? Does ‘collection date’ refer to when the organism lived, when the excavation took place or when the sampling at the museum occurred?
Ancient genomes show how humans escaped Europe’s deep freeze
Currently, managers of databases such as the ENA intend geographical location to refer to where specimens were sampled for DNA or RNA analysis, and collection date to refer to when they were sampled. This also applies to other resources in the International Nucleotide Sequence Database Collaboration (INSDC), an effort to coordinate databases containing DNA and RNA sequences. Most ancient DNA researchers assume, however, that these fields refer to where and when the sampled organism lived.
These metadata-reporting problems lead to considerable confusion and inefficiencies. Researchers wanting to use published ancient DNA data often have to piece together a lot of the metadata themselves by digging through supplementary tables or by contacting the data producers11.
Several initiatives are under way to recover metadata for published ancient genomic data and systematically package them into more user-friendly resources6,7,11,12. (This includes AncientMetagenomeDir, in which J.A.F.Y. and C.W. are involved.) Extensive volunteer work on such projects provides a bandage. But the fact that such post-publication metadata curation is needed speaks to the urgency of the problem. Furthermore, there is currently little coordination between the subfields that are trying to achieve more consistent standards.
Cultural shift
Data archiving in ancient genomics is not sufficiently prioritized. Too often, it seems to be delegated to inexperienced junior researchers or performed at the last minute to comply with journals’ publishing requirements.
Portions of some genomic data sets might need to be withheld from public archiving13 — for instance, if descendant communities want to restrict data sharing or data reuse on ethical grounds14. When this is the case, it should be made explicit — for example, through the Biocultural Labels Initiative, which involves pairing sequence data with statements about community expectations around the appropriate use of biocultural collections and genomic data. But aside from these cases, comprehensive archiving of data and metadata should be standard practice.
What is most needed now is a culture shift in the ancient DNA community.
Ancient African genomes offer glimpse into early human history
In developing better standards, researchers don’t have to start from scratch. The challenges around metadata reporting are not unique to ancient DNA research. In 2008, a group of biologists formed the Genomic Standards Consortium to promote the reporting of standardized metadata for the growing body of genomes and metagenomes being deposited in data archives15. The Minimum Information about any (x) Sequence (MIxS) framework developed by the consortium, comprising checklists with standardized metadata fields that researchers must fill out when submitting genomic data, have since been adopted by the INSDC databases16.
Such checklists provide a model for ancient DNA researchers. Indeed, last year, a network of ancient DNA researchers (including J.A.F.Y. and C.W.) proposed exactly this — a Minimum Information about any Ancient Sequence (MInAS) scheme for ancient DNA.
To make such checklists effective, the ancient DNA community needs to develop them in partnership with the INSDC, museum curators, archaeologists, radiocarbon-dating specialists and so on. This would enable researchers in all subfields to establish which metadata fields are common to everyone and what is needed for each subfield.
Journal editors and research funders can help to ensure that all primary data are uploaded to public databases and annotated appropriately. Editors typically require authors to provide a ‘data accession identifier’ — a code obtained from a public database after an upload — to prove that they have complied with data-reporting standards. But reviewers and editors rarely check that the data have been archived correctly or completely. Journal guidelines should explicitly state that authors should submit to a public database all of the sequences generated in a study — not just those aligned to a reference genome — and that the archived data must be accompanied (in the same database) by at least a minimal set of metadata.
Funders such as the European Research Council and the US National Science Foundation could likewise be more explicit about appropriate standards for data archiving. Similarly, the archaeologists and museum curators providing the biological materials used in ancient DNA research could provide researchers with specimens on the condition that any data obtained from them are archived appropriately.
Data derived from existing cell lines or bacterial cultures can usually be regenerated. But with ancient remains, samples are always limited and often rare. Second tries are not always possible or desirable — say, if researchers have to destructively resample a bone or a tooth. All science should be reproducible. But for ancient genomics especially, everyone in the field stands to benefit if the data derived from these finite resources is handled with more care.
Some researchers worry that if AI systems become conscious and people neglect or treat them poorly, they might suffer.Credit: Pol Cartie/Sipa/Alamy
The rapid evolution of artificial intelligence (AI) has brought to the fore ethical questions that were once confined to the realms of science fiction: if AI systems could one day ‘think’ like humans, for example, would they also be able to have subjective experiences like humans? Would they experience suffering, and, if so, will humanity be equipped to properly care for them?
A group of philosophers and computer scientists are arguing that AI welfare should be taken seriously. In a report posted last month on the preprint server arXiv1, ahead of peer review, they call for AI companies to not only assess their systems for evidence of consciousness and the capacity to make autonomous decisions, but also to put in place policies for how to treat the systems if these scenarios become reality.
If AI becomes conscious: here’s how researchers will know
They point out that failing to recognize that an AI system has become conscious could lead people to neglect it, harming it or causing it to suffer.
Some think that, at this stage, the idea that there is a need for AI welfare is laughable. Others are sceptical, but say it doesn’t hurt to start planning. Among them is Anil Seth, a consciousness researcher at the University of Sussex in Brighton, UK. “These scenarios might seem outlandish, and it is true that conscious AI may be very far away and might not even be possible. But the implications of its emergence are sufficiently tectonic that we mustn’t ignore the possibility,” he wrote last year in the science magazine Nautilus. “The problem wasn’t that Frankenstein’s creature came to life; it was that it was conscious and could feel.”
The stakes are getting higher as we become increasingly dependent on these technologies, says Jonathan Mason, a mathematician based in Oxford, UK, who was not involved in producing the report. Mason argues that developing methods for assessing AI systems for consciousness should be a priority. “It wouldn’t be sensible to get society to invest so much in something and become so reliant on something that we knew so little about — that we didn’t even realize that it had perception,” he says.
People might also be harmed if AI systems aren’t tested properly for consciousness, says Jeff Sebo, a philosopher at New York University in New York City and a co-author of the report. If we wrongly assume a system is conscious, he says, welfare funding might be funnelled towards its care, and therefore taken away from people or animals that need it, or “it could lead you to constrain efforts to make AI safe or beneficial for humans”.
A turning point?
The report contends that AI welfare is at a “transitional moment”. One of its authors, Kyle Fish, was recently hired as an AI welfare researcher by the AI firm Anthropic, based in San Francisco, California. This is the first such position of its kind designated at a top AI firm, according to authors of the report. Anthropic also helped to fund initial research that led to the report. “There is a shift happening because there are now people at leading AI companies who take AI consciousness and agency and moral significance seriously,” Sebo says.
Nature, Published online: 10 December 2024; doi:10.1038/d41586-024-03859-4
This week’s excerpts from Nature’s archive feature reviews of a visit to the Lick Observatory in California and a children’s adaptation of a book on anthropology.
Tracking methane emissions accurately is crucial for shaping environmental policies and regulations. This colourless and odourless gas, which is the main component of natural gas and a potent greenhouse gas, is emitted from a variety of sources, including oil drilling and farming. But finding and quantifying it is inherently challenging.
A reliable system urgently needs to be put in place for methane monitoring. And there has been a lot of buzz lately around using satellites. In March, the MethaneSAT satellite was launched for this purpose. Some are heralding this technology as the next big thing in environmental monitoring.
How AI is improving climate forecasts
As someone who has spent decades working on satellite systems, I can appreciate the allure. Satellites offer the ability to cover vast expanses of land, capturing data from regions that are difficult to monitor by other means.
But, before we get too carried away, it’s worth pausing to consider what satellites can — and, more importantly, cannot — do. Although satellites can provide crucial insights into methane releases, they are not a comprehensive solution. Their effectiveness is often hampered by limited spatial resolution, atmospheric interference and the challenge of accurately identifying specific emission sources.
Satellites’ broad spatial coverage tends to come at the cost of precision. Take the Permian Basin — a prolific oil- and gas-producing area in the southwestern United States. Overlapping infrastructure, such as pipeline networks and storage facilities, combined with varying topography, fluctuating weather patterns and diverse land uses, make specific emission sources hard to pinpoint.
Weather patterns can distort satellite readings, and offshore emissions are frequently missed. Given that oceans cover more than two-thirds of our planet, this is no small oversight.
This methane-sniffing satellite will leave climate polluters nowhere to hide
My experience managing large-scale satellite projects has taught me that remote-sensing data can sometimes raise more questions than they answer. This underscores the need for complementary monitoring methods.
To verify findings and identify leaks, satellites must be paired with boots on the ground. Relying too heavily on satellite data without corroborating it risks painting an incomplete — and possibly inaccurate — picture. And modelled data should not replace on-the-ground observations.
Such a multifaceted strategy can enhance the precision of methane monitoring, meaning that decisions are based on accurate and thorough data. More must be done to ensure that global players are investing in and deploying the most accurate methods, and are placing funding intentionally behind the technology that works best.
That means taking a more realistic approach to missions such as MethaneSAT, which is a collaboration including the US Environmental Defense Fund, Harvard University in Cambridge, Massachusetts, and the New Zealand Space Agency. MethaneSAT represents a technological upgrade over previous satellites for monitoring methane. These include GHGSat, a series of satellites that monitor carbon dioxide and methane from industrial sources, and the European Space Agency’s Sentinel-5 Precursor, which is part of the Copernicus programme and equipped to detect various atmospheric gases. Nonetheless, several challenges can affect its data.
Cloud and weather conditions can mask emissions and measurements cannot be performed at night. Emissions are hard to attribute to specific sources in densely populated areas, and data processing and interpretation challenges hinder detection in areas with dense forests or at high latitudes, where reduced sunlight reflection complicates measurements.
Scientists raise alarm over ‘dangerously fast’ growth in atmospheric methane
MethaneSAT is unable to measure methane emissions over water bodies, although plans are under way to enhance its capabilities to monitor offshore methane emissions by observing sunlight glinting on the water’s surface. And for agriculture, there can be difficulties in distinguishing between emissions from livestock and those from wetlands.
To enhance MethaneSAT’s accuracy, its data should be integrated with ground and aerial efforts. Ground teams and permanent monitoring stations can verify emissions, and drones and aircraft provide detailed coverage in challenging areas. Better algorithms and machine learning could fuse satellite, aerial and ground data for more precise emission attribution. Technological advances would allow night-time and offshore detection.
Thus, the real work happens on the ground, where problems are actually solved. The US oil and natural-gas industry, for example, is working with the best minds to accelerate innovative technologies, including satellites, to detect and mitigate its methane emissions. It is also deploying response teams on the ground to quickly find and repair any leaks.
Ultimately, my concern is that in our rush to embrace satellite monitoring, we end up missing the real picture. Methane detection is complex and no single technology can cover every angle. To make a difference, we need a balanced approach — one that values both the sweeping view from above and the granular, precise work done on the ground. Because, at the end of the day, methane monitoring is too important to leave to one tool alone. Let’s make sure we get this right.
A year from now, children under the age of 16 in Australia will be barred from many social-media platforms — the highest minimum-age limit in the world. Other countries or regions have introduced similar bans and more say they’re considering them, owing to parents’ concerns that children are exposed to cyber-bullying, scams and adult content on these platforms. But researchers say there is minimal evidence to suggest such bans will keep children safe from online harm.
The Australian government says that social media is impacting children’s wellbeing. It hasn’t said which platforms will be off-limits under the new law, but the legislation will include those that allow users to post content and interact with two or more users on a platform, such as Snapchat, TikTok and X (formerly known as Twitter). Social-media companies could face fines of up to Aus$49.5 million (US$32 million) if they don’t take “reasonable steps” to prevent children younger than the minimum age from signing up for accounts.
Many parents have applauded the tough approach, but researchers aren’t convinced banning access to social media will solve the problems it is intended to address. In October, dozens of researchers penned a letter to the Australian government arguing that a blanket ban was too blunt and that addressing online risks requires a nuanced, evidence-based approach.
There is a lack of evidence to suggest that a ban will be effective, says Andrew Przybylski, a psychologist at the University of Oxford, UK, who focuses on how social media influences mental health. “It doesn’t line up with the scientific consensus,” he says.
Evidence so far
So what does the research show? A 2023 report by the US National Academies of Sciences, Engineering, and Medicine found that social media has the potential to be harmful to adolescent health, but that there is not enough evidence to suggest that it causes negative effects at the population level. Rather than bringing in blanket bans and age restrictions, the report recommends that social-media companies adopt new standards to improve the platforms’ transparency, as well as better reporting systems to tackle online abuse.
Australia is one of several countries or regions to attempt to impose social-media restrictions on children. In 2023, France introduced a law that prohibits children under the age of 15 from signing up for social-media accounts without parental consent, although it is yet to be enforced. The US state of Florida signed a bill in March that seeks to ban social-media accounts for children younger than 14 years old, but the move is being challenged in the district court over concerns about free speech. And in October, Norway announced plans to increase the minimum age for social-media use from 13 to 15 years old.
Studies suggest that children are already finding ways around existing age limits. A 2022 report by the UK government’s Office of Communications found that 60% of children aged between 8 and 11 who use these platforms have their own profiles, despite most platforms having an age limit of 13 years old. Furthermore, young users do not need an account to browse some social-media sites, such as TikTok, and can use their parents’ logins to access content on more restrictive sites, says Stephanie Wescott, a researcher at Monash University in Melbourne, Australia, who focuses on gender-based violence in schools. “There are huge enforceability issues,” she says.
Online community
Because few jurisdictions have banned social media for children, few studies have explored whether such restrictions protect children against online harassment, bullying and harmful content. There is, however, evidence that social media offers adolescents some benefits.
In a 2022 survey conducted in the United States by the Pew Research Center, based in Washington DC, roughly 80% of 13–17-year-olds surveyed said that social media made them feel more connected to what’s happening in their friends’ lives. Among the 32% of respondents who reported that social media has a mostly positive impact on them, almost half cited connections and socializing as the main reasons. Almost 60% said that social media had a neutral effect on them, whereas only 9% found it mostly negative.
For some children, particularly those in minority groups and those living in remote areas, social media is a “lifeline”, because it gives them access to communities and support systems they might not have at home or at school, says Lisa Given, an information scientist at RMIT University in Melbourne who specializes in human behaviour. Australia’s tough social-media restrictions could isolate these children. “We’re going to need many more interventions in terms of support and care for those kids who are now banned from these platforms,” she says.
Przybylski worries that the country’s blunt approach will only push vulnerable children to corners of the Internet where they are more likely to be exposed to harm, such as unmoderated chat rooms.
Westcott says governments should focus on educating children from an early age about the pitfalls of social media and how to navigate the online world more critically.
Evolutionary geneticist Mary-Claire King did not anticipate the impact of her discovery.Credit: Rina Castelnuovo/New York Times/Redux/eyevine
When Mary-Claire King embarked on a painstaking 17-year-long hunt for a gene linked to breast cancer, she had no inkling that its discovery would be saving lives some three decades later.
King, an evolutionary geneticist, was trying to solve the mystery of why breast cancer was common in some families. This was during the 1970s, decades before the first human genome was sequenced. In the absence of modern tools such as PCR tests, sequencing and mapping genes took a heroic effort. Cancer researchers at the time were mostly studying tumour-causing viruses, but several individuals having the disease across generations of the same family suggested that considerable danger could lurk in the human genome, too.
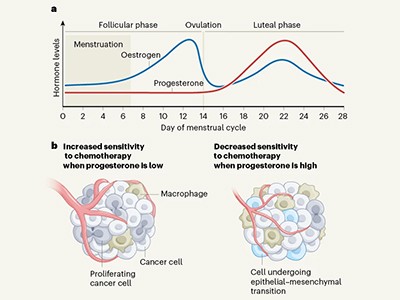
What is the best time of the month to treat breast cancer?
“The worldwide impact of something like this just never crossed my mind,” says King, who is at the University of Washington in Seattle. “I was absolutely gobsmacked.” King named the gene BRCA1. Since then, it has become clear that mutations in BRCA1 are responsible for about 35% of hereditary breast cancers, and that genetic variants of it and a related gene called BRCA2 are also linked to ovarian, prostate and pancreatic cancers. Drugs have been developed that target cancers with these variants, and genetic tests are available to identify people who are at risk.
But looking back on the impact of BRCA1’s discovery also highlights how far there still is to go. Too few people have access to genetic tests and, even when they do, they have few options to reduce their risk of cancer. Researchers must advocate for and study ways to improve access and to expand the cancer-prevention options available to people who carry BRCA1 and BRCA2 mutations.
Huge leap in breast cancer survival rat
BRCA1 encodes a protein that is important for repairing damaged DNA. Although King identified the BRCA1 gene and pinpointed its location1 in 1990, the team that first sequenced it in 1994 included researchers at the precision-medicine firm Myriad Genetics in Salt Lake City, Utah2. Myriad promptly applied for patents on the gene and used this intellectual property to prevent competitors from developing tests for cancer-associated BRCA1 mutations. The high price tag of Myriad’s genetic tests kept them out of many people’s reach, until a landmark US Supreme Court decision in June 2013 found that such gene patents were invalid.
Following the court’s decision, test prices in the United States plummeted from around US$3,800 to $250, as other providers surged into the field. Yet, testing remains limited, despite studies3 finding that expanding BRCA1 and BRCA2 testing to all women could be cost-effective, particularly for those screened between the ages of 20 and 35. There are several reasons for this, including limited health-care access and concerns about privacy. Lack of awareness among primary-care physicians about genetic testing and conflicting guidelines from professional organizations about who should be tested contribute, too. For now, however, even in places where testing is an option, it is often made available only to those at high risk of carrying a cancer-associated form of BRCA1, including people with a high rate of cancer in their family (see ‘Testing times’).
Source: Ref. 4
Many who are eligible do not get tested for BRCA1 and BRCA2 mutations: one US study4 found that only about 35% of eligible individuals with ovarian cancer and 56% of eligible people with breast cancer had been tested. Other problems limit the tests’ practical benefits, too. Reports provided to physicians and people with cancer are often unnecessarily complicated, because they list not only mutations known to increase risk, but also any other unusual DNA sequences in the genes — even if their relevance is unknown. Many tests also provide data on genes unrelated to cancer, launching fresh medical odysseys for people already dealing with a cancer diagnosis. When King accompanied a friend diagnosed with breast cancer to a clinical appointment, the attending doctor waved off suggestions for BRCA1 testing. “The difficulty with genetic tests,” they said, “is that they simply beget more tests.”
This scientist treated her own cancer with viruses she grew in the lab
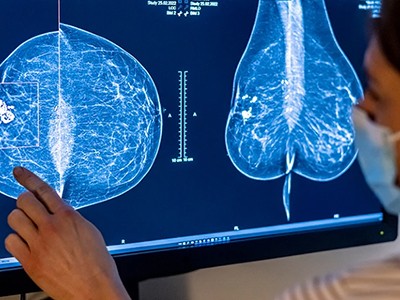
Simplifying tests and equipping medical staff with the knowledge to interpret the results could improve uptake. People who learn that they carry worrisome BRCA1 mutations need better options to either prevent cancer from developing or intercept it at an early stage. This is particularly crucial for reducing the risk of ovarian cancer and aiding its early detection. Whereas mammograms can detect some breast tumours early, there is no equivalent test for ovarian cancer, which is often diagnosed at late stages. At present, cancer detection and prevention are typically achieved by careful monitoring or, in some cases, surgery to remove the breasts and ovaries. “When I see a 25-year-old woman newly found to have a BRCA1 mutation, I’m mostly having the same conversations now that I did long ago for her options for risk reduction,” says Susan Domchek, a breast-cancer specialist at the University of Pennsylvania Perelman School of Medicine in Philadelphia. “We have a lot of work to do.”
To improve on this, researchers must develop better means of detecting cancers early, and learn more about the biology of early tumours and why some will go on to become malignant whereas others do not. They must also investigate ways to treat people at earlier stages — an effort that will require learning more about early cancers’ biological hallmarks. By contrast, most treatments are first developed for and tested in people who have advanced disease.
By filling the gaps on testing and giving people with harmful mutations better ways to reduce their risk, BRCA1 and BRCA2 testing could become a model for how genetic tests for other cancer risk factors should be implemented. Then, King’s crucial discovery will save even more lives.
Much of the excitement about AI over the past decade has come from the achievements of neural networks — systems built on an analogy of how the human brain processes information through collections of neurons. Deep learning, in which data pass through many layers of a neural network, was what led to the creation of the chatbot ChatGPT. The sperm whale, elephant and marmoset studies, however, used earlier forms of AI known as decision trees and random forests.
A decision tree is a classification algorithm that looks like a flow chart. It might ask, for example, whether the sound it has been given has a frequency above a certain value. If yes, it might then ask whether the call lasts for a certain length of time, and so on, until it has decided whether the call matches the acoustic variables it was trained to look for using human-labelled data sets. A random forest is a collection of many decision trees, each constructed from a randomly chosen subset of the data.
Kurt Fristrup, an evolutionary biologist at Colorado State University who wrote the random-forest algorithm for the elephant project, says that tree-based algorithms have several advantages for this kind of work. For one, they can work with less information than is required to train a neural network, and even thousands of hours’ of recordings of animal calls is still a relatively small data set. Furthermore, because of the way that tree-based algorithms break down the variables, they’re not likely to be thrown off by mislabelled or unlabelled data.
The random forest also provides a way to verify that similar calls match: different calls that show the same features should each end up in the same ‘leaf’ of an individual tree. “Since there were on the order of a thousand of these trees, you get a fairly fine-grained measure of how similar two calls are by how often they landed in the same leaf,” Fristrup says.
An elephant reacts to the playback of a call that was originally addressed to her. Credit: Mickey Pardo
An elephant reacts to the playback of a call that was originally addressed to her. Credit: Mickey Pardo
It is also easier to see how a random-forest algorithm came to a particular conclusion than it is with deep learning, which can produce answers that leave scientists scratching their heads about how the model reached its decision. “Deep-learning models make it possible or even easy to get all kinds of results that we can’t really get any other way,” Fristrup says. But if scientists don’t understand the reasoning behind it, they might not learn “what we would have learnt had we got into it by the older, less efficient, and less computationally intense path” of a random forest, he says.
Despite this, the ability of a neural network to generalize from a relatively small, labelled data set and discover patterns by examining large amounts of unlabelled data is appealing to many researchers.
Machine-learning specialist Olivier Pietquin is the AI research director at the Earth Species Project, an international team headquartered in Berkeley, California, that is using AI to decode the communications of animal species. He wants to take advantage of neural networks’ ability to generalize from one data set to another by training models using not only a large range of sounds from different animals, but also other acoustic data, including human speech and music.
The hope is that the computer might derive some basic underlying features of sound before building on that understanding to recognize features in animal vocalizations specifically. This is the same way in which an image-recognition algorithm trained on pictures of human faces learns some basic characteristics of pixels that describe first an oval and then an eye. The algorithm can then take those basics and recognize the face of a cat, even if human faces make up most of its training data.
Olivier Pietquin (back row, second left) and other members of the Earth Species Project are attempting to decode animal communication. Credit: Earth Species Project
Olivier Pietquin (back row, second left) and other members of the Earth Species Project are attempting to decode animal communication. Credit: Earth Species Project
“We could imagine using speech data and hope that it will transfer to any other animal that has a vocal tract and vocal cords,” Pietquin says. The whistle made by a flute, for example, might be similar enough to a bird whistle that the computer could make inferences from it.
A model trained in this way could be useful for identifying what sounds convey information and which ones are just noise. To work out what the calls might mean, however, still requires a person to observe the animal’s behaviour and add labels to what the computer has identified. Identifying speech, which is what researchers are currently trying to achieve, is just a first step towards comprehending it. “Understanding is really a tough step,” Pietquin says.