I can tell this question comes from an honest place of wanting to reduce the harm you cause through your individual interactions with AI software, which we know is quite resource-intensive. But first, take a step back with me for a moment and free yourself from the guilt of existence.
I would bet serious cash you’re an avid recycler as well? Someone who knows far too much about the different types of plastics and religiously sorts it all out like an upstanding citizen?
While this is a great practice in theory, your recyclable items may actually end up getting incinerated, buried in a landfill, or tossed into the ocean. This is because waste-management sites can’t process many types of plastic, and the deluge of garbage our society generates is just too overwhelming for our current systems to deal with. So, in the case of plastic recycling, our intentions as consumers are righteous, but the actions we take often amount to little more than a daily ritual absolving ourselves of the guilt of participating in a system that contributes to pollution.
It may feel good right now to personally opt out from using energy-intensive generative AI software when you can. Even so, you may not be able to avoid it forever. Your future job could be augmented by AI in some way that’s deemed critical to your performance, and you’ll have no choice but to let it suck up power and resources so you can get your work done. Honestly, the last decade’s shift to cloud storage has intensively transformed how we approach computing as a society, and I don’t know anyone who’s ethically conflicted about the number of photos clogging up their Apple iCloud storage. The reality is that personal, consumer decisions have less of an impact on the world than we would often like to think.
Even though I’m skeptical that abstention from AI tools by individual users will have a significant impact on the environment, this doesn’t mean the future is hopeless! If anything, I think you should be calling up your government representatives and voicing your perspective as someone who uses AI and is concerned with the technology’s impact on the long-term health of our planet. Assuming tech companies are going to continue building giant data centers—and they are—we should at least push for sustainable infrastructure, like onsite renewable energy generation and a reduction of water consumption by the computers’ cooling systems. The public deserves more transparency about how vast amounts of resources are consumed at these private sites that power our AI tools.
At your service, Reece
Seeking advice on how to navigate the world of artificial intelligence tools? Submit any questions you’d like Reece Rogers to answer to [email protected], and use the subject line The Prompt.
Whenever we go online, we might find ourselves part of an experiment — without knowing it. Digital platforms track what users do and how they respond to features. Increasingly, these tests are having real-world consequences for its participants.
I’ve seen this in my own research on the gig economy, studying job-listing platforms that offer paid tasks and jobs to freelancers (H. A. Rahman et al. Acad. Mgmt. J. 66, 1803–1830; 2023). Platforms experimented with using different methods for scoring people’s work, as well as changing how their skills would be listed on their profile page and how they could interact with their contractors. These changes affected people’s ratings and the amount of work they received.
How to harness AI’s potential in research — responsibly and ethically
Twenty years ago, such experimentation was transparent. Gig workers could opt in or out of tests. But today, these experiments are done covertly. Gig workers waive their rights when they create an account.
Being experimented on can be disconcerting and disempowering. Imagine that, every time you enter your office, it has been redesigned. So has how you are evaluated, and how you can speak with your superiors, but without your knowledge or consent. Such continual changes affect how you do and feel about your job.
Gig workers expressed that, after noticing frequent changes on the listing platforms that were made without their consent, they started to see themselves as laboratory rats rather than valued users. Because their messages were blocked by chatbots, they were unable to speak to the platform to complain or opt out of the changes. Frustration flared and apathy set in. Their income and well-being declined.
This is concerning, not only because of how affects gig workers, but also because academics are increasingly becoming involved in designing digital experiments. Social scientists follow strict Institutional Review Board (IRB) procedures that govern the ethics of experiments involving people — such as informing them and requiring consent — but these rules don’t apply to technology companies. And that’s leading to questionable practices and potentially unreliable results.
AI to the rescue: how to enhance disaster early warnings with tech tools
Technology companies use their terms of service to authorize them to collect data without any obligation to inform people that they were involved, or provide any opportunity for them to withdraw. Thus, digital experimentation faces scant oversight.
Given that technology companies reach millions of people, experiments using their data can be informative. For example, a 2022 study by academics and the career platform LinkedIn answered questions about how weak links in people’s social networks contribute to job outcomes (K. Rajkumar et al. Science377, 1304–1310; 2022). The platform varied the algorithm it uses to suggest new contacts for more than 20 million users. Those people were unaware, despite this potentially affecting their job prospects.
Scientists themselves can be subject to such hidden practices. For example, in September, the journal Science acknowledged that studies it had published exploring political polarization using user feeds from the social-media platform Facebook were compromised when the technology giant changed its algorithm during the study period without the scientists’ knowledge (H. Holden Thorp and V. Vinson Science385, 1393; 2024).
Academics must be more wary about the data that they generate through collaborations with technology companies and rethink how they conduct this research. An ethically robust framework is needed for science–industry collaboration to ensure that experimentation does not jeopardize public trust in science.
Chain retraction: how to stop bad science propagating through the literature
First, scholars should engage in a thorough ethics check by auditing potential partners and making sure that they follow IRB principles. They could work with or create intermediary watchdog organizations, just as Fairwork, based in Oxford, UK, safeguards gig-workers’ rights, which can audit experimentation practices and introduce transparency into data collection. They can diffuse and enforce ethical norms of experimentation, inform industry partners on how to conduct ethically sound research and hold them to account.
Second, scholars need to evaluate the social effects of experimentation to study and mitigate any potential harm. This is not trivial, because experiments rarely consider the well-being of participants and don’t assess potential unintended consequences.
Technology companies should establish their own internal review boards, which have the authority to assess and vet experiments. Industry needs to instil a culture of ethically robust experimentation, including understanding the potential adverse effects participants might face.
Regulation is crucial. One good example is the European Union’s Artificial Intelligence Act, which centres consumers’ right to data privacy and protection and aims to establish “a safe and controlled space for experimentation”.
Consumers and users should form third-party organizations, similar to the unions used by gig workers, to rate companies on whether they request consent and allow people to opt out of experimentation, and how transparent they are.
Driving forward the frontier of science–industry experimentation requires practices, rules and regulations that ensure mutually beneficial outcomes for people, organizations and society.
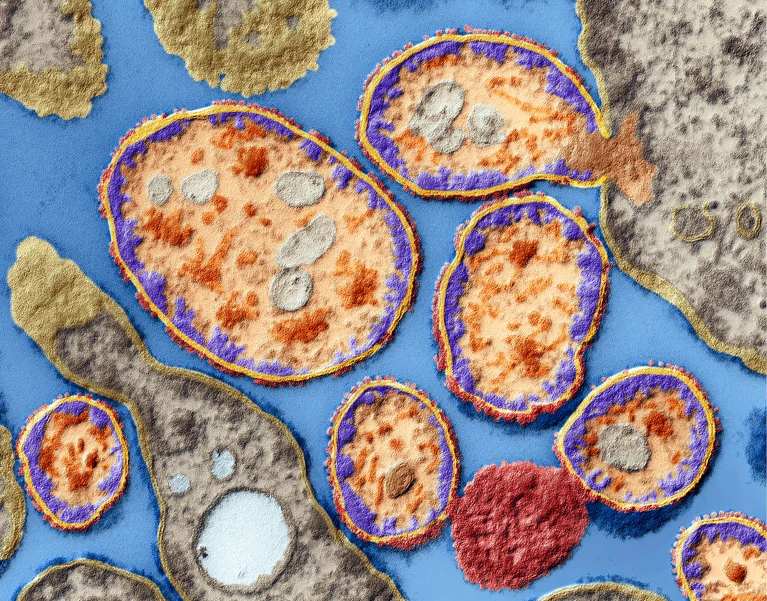
Viruses such as measles (pictured here) can be used to attack cancerous cells. Credit: Eye Of Science/Science Photo Library
A scientist who successfully treated her own breast cancer by injecting the tumour with lab-grown viruses has sparked discussion about the ethics of self-experimentation.
Beata Halassy discovered in 2020, aged 49, that she had breast cancer at the site of a previous mastectomy. It was the second recurrence there since her left breast had been removed, and she couldn’t face another bout of chemotherapy.
Halassy, a virologist at the University of Zagreb, studied the literature and decided to take matters into her own hands with an unproven treatment.
A case report published in Vaccines in August1 outlines how Halassy self-administered a treatment called oncolytic virotherapy (OVT) to help treat her own stage 3 cancer. She has now been cancer-free for four years.
In choosing to self-experiment, Halassy joins a long line of scientists who have participated in this under-the-radar, stigmatized and ethically fraught practice. “It took a brave editor to publish the report,” says Halassy.
Up-and-coming therapy
OVT is an emerging field of cancer treatment that uses viruses to both attack cancerous cells and provoke the immune system into fighting them. Most OVT clinical trials so far have been in late-stage, metastatic cancer, but in the past few years they have been directed towards earlier-stage disease. One OVT, called T-VEC, has been in approved in the United States to treat metastatic melanoma, but there are as yet no OVT agents approved to treat breast cancer of any stage, anywhere in the world.
Halassy stresses that she isn’t a specialist in OVT, but her expertise in cultivating and purifying viruses in the laboratory gave her the confidence to try the treatment. She chose to target her tumour with two different viruses consecutively — a measles virus followed by a vesicular stomatitis virus (VSV). Both pathogens are known to infect the type of cell from which her tumour originated, and have already been used in OVT clinical trials. A measles virus has been trialled against metastatic breast cancer.
Halassy had previous experience working with both viruses, and both have a good safety record. The strain of measles she chose is used extensively in childhood vaccines, and the strain of VSV induces, at worst, mild influenza-like symptoms.
Halassy’s experience with self-treatment has changed the focus of her research. Credit: Ivanka Popić
Over a two-month period, a colleague administered a regime of treatments with research-grade material freshly prepared by Halassy, injected directly into her tumour. Her oncologists agreed to monitor her during the self-treatment, so that she would be able to switch to conventional chemotherapy if things went wrong.
The approach seemed to be effective: over the course of the treatment, and with no serious side effects, the tumour shrank substantially and became softer. It also detached from the pectoral muscle and skin that it had been invading, making it easy to remove surgically.
How a trove of cancer genomes could improve kids’ leukaemia treatment
Analysis of the tumour after removal showed that it was thoroughly infiltrated with immune cells called lymphocytes, suggesting that the OVT had worked as expected and provoked Halassy’s immune system to attack both the viruses and the tumour cells. “An immune response was, for sure, elicited,” says Halassy. After the surgery, she received a year’s treatment with the anticancer drug trastuzumab.
Stephen Russell, an OVT specialist who runs virotherapy biotech company Vyriad in Rochester, Minnesota, agrees that Halassy’s case suggests the viral injections worked to shrink her tumour and cause its invasive edges to recede.
But he doesn’t think her experience really breaks any new ground, because researchers are already trying to use OVT to help treat earlier-stage cancer. He isn’t aware of anyone trying two viruses sequentially, but says it isn’t possible to deduce whether this mattered in an ‘n of 1’ study. “Really, the novelty here is, she did it to herself with a virus that she grew in her own lab,” he says.
Ethical dilemma
Halassy felt a responsibility to publish her findings. But she received more than a dozen rejections from journals — mainly, she says, because the paper, co-authored with colleagues, involved self-experimentation. “The major concern was always ethical issues,” says Halassy. She was particularly determined to persevere after she came across a review highlighting the value of self-experimentation2.
That journals had concerns doesn’t surprise Jacob Sherkow, a law and medicine researcher at the University of Illinois Urbana-Champaign who has examined the ethics of researcher self-experimentation in relation to COVID-19 vaccines.
Huge leap in breast cancer survival rate
The problem is not that Halassy used self-experimentation as such, but that publishing her results could encourage others to reject conventional treatment and try something similar, says Sherkow. People with cancer can be particularly susceptible to trying unproven treatments. Yet, he notes, it’s also important to ensure that the knowledge that comes from self-experimentation isn’t lost. The paper emphasizes that self-medicating with cancer-fighting viruses “should not be the first approach” in the case of a cancer diagnosis.
“I think it ultimately does fall within the line of being ethical, but it isn’t a slam-dunk case,” says Sherkow, adding that he would have liked to see a commentary fleshing out the ethics perspective, published alongside the case report.
Halassy has no regrets about self-treating, or her dogged pursuit of publication. She thinks it is unlikely that someone would try to copy her, because the treatment requires so much scientific knowledge and skill. And the experience has given her own research a new direction: in September she got funding to investigate OVT to treat cancer in domestic animals. “The focus of my laboratory has completely turned because of the positive experience with my self-treatment,” she says.
Researchers have voiced concerns after South Africa updated its health-research ethics guidelines to include a new section on heritable (or germline) human genome editing.
Scientists say this could put the nation one step closer to accepting the controversial technique — which involves introducing genetic changes to sperm, eggs or embryos, such that the modifications will be passed down through successive generations. The research ethics guidelines were updated in May, but the news became more widely known last month.
Currently, no country explicitly allows heritable human genome editing in clinical settings. It is not clear to what extent South Africa’s scientific community was consulted on the changes.
Nature has requested comment from South Africa’s department of health, which published the revised guidelines, and from the National Health Research Ethics Council, a statutory body under the National Health Act, which drafted them. No comment was received by the time this article was published.
“The decision to amend the South African Ethics in Health Research Guidelines to facilitate research to create genetically modified children is baffling,” says Françoise Baylis, a bioethicist at Dalhousie University in Halifax, Canada who wrote about the change in an article in The Conversation.
“I know of no other country that explicitly permits this type of research and can’t understand why South Africa would want to be the first to do so,” adds Baylis, who is also a member of the World Health Organization’s advisory committee on developing global standards for governance and oversight of human genome editing.
There is an international consensus among researchers that the practice is not acceptable in the clinical setting. Such editing could prevent inherited diseases, such as cystic fibrosis and sickle-cell disease, but it poses significant ethical concerns and safety challenges.
In 2018, He Jiankui, a biophysicist then at the Southern University of Science and Technology of China in Shenzhen, claimed to have helped make the world’s first genome-edited babies. That caused a global outcry. He was jailed in 2020 for “illegal medical practice”.
In 2019, an international group of ethicists and researchers called for a moratorium on the clinical use of heritable human genome editing, which was supported by the US National Institutes of Health. The organizing committee of the third international summit on human genome editing said in 2023 that heritable human genome editing “remains unacceptable at this time”.
Before and after
South Africa’s previous guidelines from 2015 had a relatively small section on genomic research. In the latest version, a new section on heritable human genome editing has been added.
The updated text says that heritable human genome editing must have a “clear and compelling scientific and medical rationale, focusing on the prevention of serious genetic disorders and immunity against serious diseases”, be transparent, obtain informed consent from all parties and have stringent ethical oversight. “The potential benefits to individuals and society should outweigh risks and uncertainties,” the guidelines say.
Human embryo science: can the world’s regulators keep pace?
Furthermore, researchers must “commit to ongoing monitoring of individuals born as a result of [heritable human genome editing] to assess their health, well-being and potential unforeseen consequences”.
The guidelines note that researchers must adhere to all relevant laws governing such research. However, there are different views on whether South Africa’s law, the National Health Act actually allows for heritable human genome editing.
Is it even legal?
Jantina De Vries, director of the EthicsLab at the University of Cape Town, is among those who says that heritable human genome editing is illegal in clinical settings. She cautions against reading too much into the amended guidelines. “What has changed is the research ethics guidelines, not the legality of heritable human genome editing in any other sense beyond research,” she says.
By contrast, Bonginkosi Shozi, a bioethicist and health-law scholar at Stanford Law School’s Center for Law and the Biosciences in California, takes the view that the law already allows heritable human genome editing, and that the revised research ethics guidelines have now caught up with the law.
In a 2020 study in the South African Journal of Science1, Shozi and four co-authors wrote: “Given its potential to improve the lives of the people of South Africa, human germline editing should be regulated, not banned.”
Shozi told Nature: “The [updated] guidelines should be seen as recognizing the legal reality in South Africa and providing guidance to health-research ethics committees that is cognizant of that reality,” he says.
Baylis says that she is concerned that advocates of heritable genome editing might use the new guidelines to push for further legal amendments that will explicitly permit the creation of genetically modified children.
“Globally, there is a reluctance to accept heritable genome editing at this point in time,” says Michael Pepper, director of the Institute for Cellular and Molecular Medicine at the University of Pretoria. “We need to examine in more detail why our guidelines have been published in the way that they have.”
When I wrote about Anduril in 2018, the company explicitly said it wouldn’t build lethal weapons. Now you are building fighter planes, underwater drones, and other deadly weapons of war. Why did you make that pivot?
We responded to what we saw, not only inside our military but also across the world. We want to be aligned with delivering the best capabilities in the most ethical way possible. The alternative is that someone’s going to do that anyway, and we believe that we can do that best.
Were there soul-searching discussions before you crossed that line?
There’s constant internal discussion about what to build and whether there’s ethical alignment with our mission. I don’t think that there’s a whole lot of utility in trying to set our own line when the government is actually setting that line. They’ve given clear guidance on what the military is going to do. We’re following the lead of our democratically elected government to tell us their issues and how we can be helpful.
What’s the proper role for autonomous AI in warfare?
Luckily, the US Department of Defense has done more work on this than maybe any other organization in the world, except the big generative-AI foundational model companies. There are clear rules of engagement that keep humans in the loop. You want to take the humans out of the dull, dirty, and dangerous jobs and make decisionmaking more efficient while always keeping the person accountable at the end of the day. That’s the goal of all of the policy that’s been put in place, regardless of the developments in autonomy in the next five or 10 years.
There might be temptation in a conflict not to wait for humans to weigh in, when targets present themselves in an instant, especially with weapons like your autonomous fighter planes.
The autonomous program we’re working on for the Fury aircraft [a fighter used by the US Navy and Marine Corps] is called CCA, Collaborative Combat Aircraft. There is a man in a plane controlling and commanding robot fighter planes and deciding what they do.
What about the drones you’re building that hang around in the air until they see a target and then pounce?
There’s a classification of drones called loiter munitions, which are aircraft that search for targets and then have the ability to go kinetic on those targets, kind of as a kamikaze. Again, you have a human in the loop who’s accountable.
War is messy. Isn’t there a genuine concern that those principles would be set aside once hostilities begin?
Humans fight wars, and humans are flawed. We make mistakes. Even back when we were standing in lines and shooting each other with muskets, there was a process to adjudicate violations of the law of engagement. I think that will persist. Do I think there will never be a case where some autonomous system is asked to do something that feels like a gross violation of ethical principles? Of course not, because it’s still humans in charge. Do I believe that it is more ethical to prosecute a dangerous, messy conflict with robots that are more precise, more discriminating, and less likely to lead to escalation? Yes. Deciding not to do this is to continue to put people in harm’s way.
Photograph: Peyton Fulford
I’m sure you’re familiar with Eisenhower’s final message about the dangers of a military-industrial complex that serves its own needs. Does that warning affect how you operate?
That’s one of the all-time great speeches—I read it at least once a year. Eisenhower was articulating a military-industrial complex where the government is not that different from the contractors like Lockheed Martin, Boeing, Northrop Grumman, General Dynamics. There’s a revolving door in the senior levels of these companies, and they become power centers because of that inter-connectedness. Anduril has been pushing a more commercial approach that doesn’t rely on that closely tied incentive structure. We say, “Let’s build things at the lowest cost, utilizing off-the-shelf technologies, and do it in a way where we are taking on a lot of the risk.” That avoids some of this potential tension that Eisenhower identified.
A group of sex industry professionals and advocates issued an open letter to EU regulators on Thursday, claiming that their views are being overlooked in vital discussions on policing AI technology despite also being implicated in AI’s momentous rise.
In response to European internet regulations, a collective of adult industry members—including sex workers, erotic filmmakers, sex tech enterprises, and sex educators—urged the European Commission to include them in future negotiations shaping AI regulations, according to the letter, seen by WIRED.
The group includes erotic filmmaker Erika Lust’s company as well as the European Sex Workers’ Rights Alliance campaign group, and is signed the Open Mind AI initiative. The group aims to alert the commission of what it says is a “critical gap” in discussions on AI regulation. Those coordinating the campaign say that current discussion strategy risks excluding first-hand perspectives on adult content and overregulating an already-marginalized community.
“AI is evolving every day [and] we see new developments at every corner,” said Ana Ornelas, a Berlin-based erotic author and educator who goes by the pseudonym Pimenta Cítrica, and who is one of the leaders of the initiative. “It is natural that people will turn to this new technology to satisfy their fantasies.”
But deepfakes are now a major AI threat. Ninety six percent of them feature nonconsensual “porn,” mostly of women and girls. It is “extremely harmful” to those targeted, as well as to porn performers, says Ornelas. “It’s a threat both to their human integrity and their livelihood,” she adds. “But the way the landscape is posed, adult content creators, sex workers, and educators are getting the shorter end of the stick on both sides of the spectrum.” She says that she fears banishing all adult content will sweep legitimately created content away with nonconsensual material and push people to AI models with no filters at all.
On August 1, the European Commission introduced what it called the world’s first comprehensive legislation on AI. The aim, it said, is to cultivate responsible use of AI across the bloc. It followed earlier EU legislation policing illegal and harmful activities on digital platforms. But the initiative’s organizers say regulators don’t understand the adult industry, risking censorship, draconian measures, and misunderstandings.
“We can offer the right insight to policymakers so they can regulate in a way that safeguards fundamental rights, freedom, and fosters a more sex-positive online environment,” says Ornelas. The European Commission did not immediately respond to a WIRED request for comment.
Sex workers and porn performers have already reported censorship and discrimination linked to global legislation clamping down on sex trafficking and banks limiting their services. Adult industry members, including sex educators, have also had to grapple with suspensions and removals from tech platforms.
“There’s a lack of awareness of how policies impact our livelihoods,” says Paulita Pappel, an adult filmmaker and an organizer of the initiative. “We are facing discrimination, and if regulators are trying to protect the rights of people, it would be nice if they could protect the digital rights of everyone.”
Rapa Nui is known for its giant stone figures, called moai.Credit: Sébastien Lecocq/Alamy
More than 800 years ago, Polynesians sailed thousands of kilometres across the Pacific Ocean to one of the most remote islands on Earth, Rapa Nui.
Now, a study of ancient genomes from descendants of these voyagers has answered key questions about the island’s history, dispelling the idea of a population collapse hundreds of years ago, and confirming precolonial contact with Indigenous Americans.
Ancient voyage carried Native Americans’ DNA to remote Pacific islands
The theory that the early Indigenous inhabitants of Rapa Nui — also known as Easter Island — ravaged its ecosystem and caused the population to crash before the arrival of Europeans in the early eighteenth century was popularized in the 2006 book Collapse, by geographer Jared Diamond, but some other scholars have since criticized that theory.
The latest analysis, published on 11 September in Nature1, “serves as the final nail in the coffin of this collapse narrative”, says Kathrin Nägele, an archaeogeneticist at the Max Planck Institute for Evolutionary Anthropology in Leipzig, Germany. “It’s correcting the image of Indigenous people.”
The study was done with the endorsement of and input from officials and Indigenous community members in Rapa Nui. The authors say that their data could contribute to the repatriation of the remains sampled in the study, which were collected in the nineteenth and twentieth centuries and sit in a Paris museum.
Answers from DNA
After settling Rapa Nui by around ad 1200, ancient Polynesian people developed a flourishing culture famous for its hundreds of colossal stone statues, called moai.
When Europeans first reached the island in 1722, they estimated that it had a population of between 1,500 and 3,000 people and found a landscape denuded of the palm-tree forests that would have once covered the island. By the late nineteenth century, the Indigenous population, called the Rapanui, had dwindled to 110 people, owing to a smallpox outbreak and the kidnap of one-third of the inhabitants by Peruvian slave traders.
The ‘ecocide’ theory, that a pre-contact population of 15,000 or more plundered the once-pristine island’s resources, has been challenged by researchers who have questioned humans’ role in deforestation and its effects on food production, as well as the large estimates for the population.
Indigenous groups look to ancient DNA to bring their ancestors home
Anna-Sapfo Malaspinas, a population geneticist at the University of Lausanne, Switzerland, and Víctor Moreno-Mayar, an evolutionary geneticist at the University of Copenhagen, were hopeful that ancient Rapanui DNA could address the ecocide theory, as well as another lingering question: when ancient islanders mixed with Native Americans.
Their team’s 2014 study of genomes from contemporary Rapanui identified that these people had some Native American ancestry that seemed to have been acquired before European arrival2, hinting at voyages to the Americas. But a 2017 study found no signs of Native American ancestry in the genomes of three individuals people who lived in Rapa Nui before 17223.
To find answers, the researchers turned to human remains in France’s National Museum of Natural History that were collected in the nineteenth and early twentieth centuries. Genome sequences from the teeth or inner-ear bones of 15 individuals, and comparisons with other ancient and modern populations, suggested they were Rapanui, and radiocarbon dating showed that they lived between 1670 and 1950.
No population collapse
Both ancient and modern genomes carry information about how a population’s size has changed over time. When the population is small, segments of DNA shared between individuals — which are inherited from a common ancestor — tend to be longer and more abundant, compared with DNA segments from periods when numbers are higher.
In the genomes of the ancient Rapanui, there were signs of a population bottleneck around the time the island was settled, as would be expected when a founder group arrives. But after that, the island’s population seemed to grow steadily until the nineteenth century.
Divided by DNA: The uneasy relationship between archaeology and ancient genomics
Translating these trajectories into actual population numbers is not straightforward, but further modelling suggested that the genetic data are not consistent with, for example, a drop from 15,000 to 3,000 people before the eighteenth century. “There’s no strong collapse,” says Malaspinas. “We’re quite confident that it did not happen.”
All the ancient Rapanui carried Native American ancestry in their genomes, which the researchers determined had probably resulted from mixing dated to the fourteenth century. The Native American segments most closely resembled DNA from ancient and modern-day inhabitants of the central Andean highlands in South America, but the dearth of ancient and modern human genomes from the Americas makes it impossible to pinpoint the people the ancient Rapanui encountered, adds Moreno-Mayar. Still, the finding that Rapanui encountered Native Americans hundreds of years before Europeans arrived is “a banger result”, says Nägele. “We can look for where this happened and who travelled.”
Community input
Keolu Fox, a genome scientist at the University of California, San Diego, says the finding that Rapanui reached the Americas will come as no surprise to Polynesian people. “We’re confirming something we already knew,” he says. “Do you think that a community that found things like Hawaii or Tahiti would miss a whole continent?”
The researchers received a similar reaction when presenting their initial findings in Rapa Nui. Malaspinas recalls being told that ‘of course we went to the Americas’. She, Moreno-Mayar and other colleagues made multiple trips to the island to consult with officials and residents throughout the study.
From Vikings to Beethoven: what your DNA says about your ancient relatives
Malaspinas and her colleagues got approval for the study from committees that oversee land use and cultural heritage on the island. The researchers sought their permission after sampling the remains in Paris — something Malasipinas now regrets. “I would do things differently if I had started the project today,” she says, adding that her team was prepared to shelve the work if the committees had said no.
Community outreach in Rapa Nui shaped the questions the project tackled, says Malaspinas, such as trying to settle the relationship between ancient and present-day Rapanui. There was also a strong interest in repatriating the remains, something the researchers hope will eventually happen.
Nägele, who works in Polynesia, thinks the researchers did a good job of engaging with people in Rapa Nui. But she adds that scientists should have a stronger role in pressuring foreign institutions to return Indigenous remains to their place of origin.
The first wave of major generative AI tools largely were trained on “publicly available” data—basically, anything and everything that could be scraped from the internet. Now, sources of training data are increasingly restricting access and pushing for licensing agreements. With the hunt for additional data sources intensifying, new licensing startups have emerged to keep the source material flowing.
The Dataset Providers Alliance, a trade group formed this summer, wants to make the AI industry more standardized and fair. To that end, it has just released a position paper outlining its stances on major AI-related issues. The alliance is made up of seven AI licensing companies, including music-copyright-management firm Rightsify, Japanese stock-photo marketplace Pixta, and generative-AI copyright-licensing startup Calliope Networks. (At least five new members will be announced in the fall.)
The DPA advocates for an opt-in system, meaning that data can be used only after consent is explicitly given by creators and rights holders. This represents a significant departure from the way most major AI companies operate. Some have developed their own opt-out systems, which put the burden on data owners to pull their work on a case-by-case basis. Others offer no opt-outs whatsoever.
The DPA, which expects members to adhere to its opt-in rule, sees that route as the far more ethical one. “Artists and creators should be on board,” says Alex Bestall, CEO of Rightsify and the music-data-licensing company Global Copyright Exchange, who spearheaded the effort. Bestall sees opt-in as a pragmatic approach as well as a moral one: “Selling publicly available datasets is one way to get sued and have no credibility.”
Ed Newton-Rex, a former AI executive who now runs the ethical AI nonprofit Fairly Trained, calls opt-outs “fundamentally unfair to creators,” adding that some may not even know when opt-outs are offered. “It’s particularly good to see the DPA calling for opt-ins,” he says.
Shayne Longpre, the lead at the Data Provenance Initiative, a volunteer collective that audits AI datasets, sees the DPA’s efforts to source data ethically as admirable, although he suspects the opt-in standard could be a tough sell, because of the sheer volume of data most modern-day AI models require. “Under this regime, you’re either going to be data-starved or you’re going to pay a lot,” he says. “It could be that only a few players, large tech companies, can afford to license all that data.”
In the paper, the DPA comes out against government-mandated licensing, arguing instead for a “free market” approach in which data originators and AI companies negotiate directly. Other guidelines are more granular. For example, the alliance suggests five potential compensation structures to make sure creators and rights holders are paid appropriately for their data. These include a subscription-based model, “usage-based licensing” (in which fees are paid per use), and “outcome-based” licensing, in which royalties are tied to profit. “These could work for anything from music to images to film and TV or books,” Bestall says.
Bioinformatician Sam Payne stumbled on a manuscript in March that included figures that, he says, looked identical to those in a paper he published in 2021.Credit: Getty
When bioinformatician Sam Payne was asked to review a manuscript on a topic relevant to his own work, he agreed — not anticipating just how relevant it would be.
The manuscript, which was sent to Payne in March, was about a study on the effect of cell sample sizes for protein analysis. “I immediately recognized it,” says Payne, who is at Brigham Young University in Provo, Utah. The text, he says, was similar to that of a paper1 he’d authored three years earlier, but the most striking feature was the plots: several were identical down to the last data point. He fired off an e-mail to the journal, BioSystems, which promptly rejected the manuscript.
In July, Payne discovered that the manuscript had been published2 in the journal Proteomics, and he alerted the editors. On 15 August, the journal retracted the paper. An accompanying statement cited “major unattributed overlap between the figures” in it and Payne’s work. In response to questions from Nature, a spokesperson for Wiley, which publishes Proteomics, said, “This paper was simultaneously submitted to multiple journals and included plagiarized images.”
AI is complicating plagiarism. How should scientists respond?
The retraction statement also stated that four of the authors said they “did not participate in the writing and submission of the article and gave no consent for publication”, and that the fifth author did not respond. However, Nature’s news team found links between several of the authors and International Publisher, a paper mill based in Moscow. Neither the authors nor International Publisher responded to Nature’s requests for comment.
The alleged plagiarism of Payne’s paper highlights systemic vulnerabilities in the global research community, says Lisa Rasmussen, editor-in-chief of the journal Accountability in Research. According to one analysis, roughly 70,000 papers with characteristics common to work produced by paper mills were published in 2022 alone.
Despite the scale of the problem, there is no Interpol equivalent for journals, nor an official authority to provide industry-wide alerts about suspicious manuscripts. “It was just a complete lucky break that the person asked to review it was the author,” Rasmussen says. “Obviously our system should not depend on that kind of serendipity.”
Carbon copy
Although some figures in the BioSystems manuscript were direct copies of those in Payne’s paper, others were simply replotted using his data, which are publicly available, he says. He shared the disconcerting experience on X, formerly known as Twitter. “Well, it happened,” he wrote. He was reviewing a manuscript, he wrote in a post, that included “a direct copy of the figures” in one of his own papers.
Source: Ref. 1 and Ref. 2
When, months later, he discovered the Proteomics paper, he posted a follow-up. “Well. It REALLY happened” — the paper that he had been asked to review had been published. Two weeks later, Proteomics retracted the paper, citing plagiarism of images.
Unlike the figures, the main text of the Proteomics paper is similar to that of Payne’s, but not identical. For example, Payne and his colleagues wrote:
“From the large population of 10,000 cells, we subsampled a given number of cells n_sample ∈ [7, 16, 20, 30, 100] and calculated S/Vest.”
The corresponding paragraph of the Proteomics paper features the same numbers and many of the same words:
“The authors calculated S/Vest using sample n = [7, 16, 20, 30, 100] cells from a population of 10,000 cells.”
The use of the third person caught Payne’s eye. He says such oddities led him to think his paper had been paraphrased using artificial intelligence (AI) to create believable but different text.
Paper pushing
In the course of reporting, Nature found links between authors of the Proteomics paper and a paper mill. Two authors, Dmitrii Babaskin and Tatyana Degtyarevskaya, both at the I.M. Sechenov First Moscow State Medical University, had separate articles3,4 retracted from the International Journal of Emerging Technologies in Learning. Both retraction statements, issued in July 2022, use the same language: “The work could be linked to a criminal paper mill selling authorships and articles for publication.”
As evidence, the statements cited the work of Brian Perron — who studies social work at the University of Michigan in Ann Arbor and also works as a misconduct sleuth — and his colleagues, who had found links between both of the retracted papers and International Publisher. Neither Babaskin nor Degtyarevskaya responded to Nature’s requests for comment about the retractions.
Publishers unite to tackle doctored images in research papers
International Publisher’s website advertises a selection of more than 10,000 manuscripts, on topics as diverse as the metallurgy of aluminium-alloy welding and the biological features of quails. Prospective buyers can see the paper’s title, and sometimes its abstracts, as well as the expected ranking in the citation database Scopus of the journal of publication. They then select an author slot, with costs ranging from about US$500 to $3,000. The company promises that titles and abstracts shown online will be “completely changed” for publication. “No one will ever be able to find the manuscript anywhere,” the website declares.
Nevertheless, in 2021, Perron and his colleagues reported on the scientific-fraud watchdog website Retraction Watch that they had identified nearly 200 published papers that probably originated from International Publisher. A number of the published titles “were almost word-for-word” the same as those listed for sale, Perron says. Many of the papers listed in the Retraction Watch report were later retracted. Asked for comment on allegations that it is a paper mill, International Publisher did not respond.
Clearing the catalogue
International Publisher removes paper listings from its online catalogue after papers are purchased. To get around this, Nature examined a database of past International Publisher paper listings, created by Perron, and combed through screenshots of the paper mill’s website taken by the non-profit organization Internet Archive, based in San Francisco, California. The search showed that the titles of multiple articles published by four of the five authors of the Proteomics study matched the titles of papers previously listed for sale by International Publisher.
Biomedical paper retractions have quadrupled in 20 years — why?
These paper listings do not include the full article text, but strong circumstantial evidence connects the paper mill’s listings to published studies. For example, a screenshot of the paper mill’s website taken in September 2021 shows that among the articles for sale was #1584, “The structure of forest vegetation on industrial dumps of different ages.” Degtyarevskaya was an author of a paper published in Ecology and Evolution5in July 2023 with a nearly identical title and matching abstract. In response to an enquiry from the news team, Ecology and Evolution said that it is now investigating the matter.
Although Nature’s news team was unable to locate a sales listing on International Publisher’s website for the Proteomics paper, Perron says that the paper has several hallmarks of paper-mill articles. Nature could not find any other studies published by the authors on the paper’s subject matter, protein analysis. Moreover, the manuscript was submitted to BioSystems while it was still under review at Proteomics. Perron says that submitting a manuscript to more than one journal simultaneously is a classic tactic of researchers trying to publish paper-mill products.
A spokesperson for Wiley did not specify whether the allegedly plagiarized Proteomics paper came from a paper mill, but said: “Our investigation confirmed that systematic manipulation of the publication process was at play.”
Check and check again
In recent years, some publishers and journals have taken extra countermeasures against plagiarism and paper mills. One such effort, developed by the International Association of Scientific, Technical and Medical Publishers (STM), a trade organization in The Hague, the Netherlands, is the STM Integrity Hub, a resource for scientific publishers that includes a ‘paper mill checker tool’ and ‘duplicate submission checker tool’. The latter is in use at more than 150 journals and scans more than 20,000 papers each month. More than 1% are identified as duplicates.
There are no metrics for how often researchers spot plagiarism of their own work, but several researchers responded to Payne’s social-media posts by sharing that they had found themselves in a similar situation.
For Payne, the prospect of paper mills taking advantage of AI is a daunting one. “This, I think, is a pretty good con,” he says. “I think it’s going to happen more.”
As a consultant in orthopaedic surgery at Khoo Teck Puat Hospital, Singapore, I’ve seen first-hand how cultural differences can be overlooked by large language models (LLMs).
Back in 2005, Singapore’s Health Promotion Board introduced categories of body mass index (BMI) tailored specifically for the local population. It highlighted a crucial issue — Asian people face a higher risk of diabetes and cardiovascular diseases at lower BMI scores compared with European and North American populations. Under the board’s guidelines, a BMI of 23 to 27.4 would be classified as ‘overweight’, a lower range than the global standard of 25 to 29.9 set by the World Health Organization (WHO).
Nature Career Guide: Faculty
I was reviewing recommendations for a person’s health plan generated by an artificial intelligence (AI) system, when I realized that it had categorized the person’s BMI of 24 as being inside conventional limits, disregarding the guidelines we follow in Singapore. It was a stark reminder of how important it is for AI systems to account for diversity.
This is one example of many. Having lived and worked in Malaysia, Singapore, the United Kingdom and the United States, I’ve gained an understanding of how cultural differences can affect the effectiveness of AI-driven systems. Medical terms and other practices that are well understood in one society can be misinterpreted by an AI system if it hasn’t been sufficiently exposed to its culture. Fixing these biases is not just a technical task but a moral responsibility, because it’s essential to develop AI systems that accurately represent the different realities of people around the world.
Identifying blind spots
As the saying goes, you are what you eat, and in the case of generative AI, these programs process vast amounts of data and amplify the patterns present in that information. Language bias occurs because AI models are often trained on data sets dominated by English-language information. This often means that a model will perform better on an English-language task than it will on those in other languages, inadvertently sidelining people whose first language is not English.
Imagine a library filled predominantly with English-language books; a reader seeking information in another language would struggle to find the right material — and so, too, do LLMs. In a 2023 preprint, researchers showed that a popular LLM performed better with English prompts than with those in 37 other languages, wherein it faced challenges with accuracy and semantics1.
Artificial-intelligence systems might not reflect important differences between cultures.Credit: Jaap Arriens/NurPhoto/Getty
Gender biases are another particularly pervasive issue in the landscape of LLMs, often reinforcing stereotypes embedded in the underlying data. This can be seen in word embeddings, a process in which words are represented by how semantically similar they are. In a 2016 preprint, Tolga Bolukbasi, a computer scientist then at Boston University in Massachusetts, and his colleagues showed how various word embeddings associated the word ‘man’ with ‘computer programmer’ and ‘woman’ with ‘homemaker’, amplifying gender stereotypes through its output2,3.
In a 2023 study, researchers prompted four LLMs with a sentence that included a pronoun and two stereotypically gendered occupations. The LLMs were 6.8 times more likely to pick a stereotypically female job when presented with a female pronoun, and 3.4 times more likely to pick a stereotypically male job with a male pronoun4.
Navigating the bias
To ensure that bias doesn’t creep into my work when using LLMs, I adopt several strategies. First, I treat AI outputs as a starting point rather than as the final product. Whenever I use generative AI to assist with research or writing, I always cross-check its results with trusted sources from various perspectives.
In a project from this Feburary that focused on developing AI-generated educational content for the prevention of diabetic neuropathy — a condition in which prolonged high blood-sugar levels causes nerve damage — I consulted peers from various backgrounds to ensure that the material was culturally sensitive and relevant to the diverse population groups in Singapore, including Malay, Chinese and Indian people.
After the AI created an initial draft of the prevention strategies, I shared the content with colleagues from each of these cultural backgrounds. My Malay colleague pointed out that the AI’s recommendations heavily emphasized dietary adjustments common in Western cultures, such as reducing carbohydrate intake, without considering the significance of rice in Malay cuisine. She suggested including alternatives such as reducing portion sizes or incorporating low-glycemic-index rice varieties that align with Malay dietary practices. Meanwhile, a Chinese colleague noted that the AI failed to address the traditional use of herbal medicine and the importance of food therapy in Chinese culture. An Indian colleague highlighted the need to consider vegetarian options and the use of spices such as turmeric, which is commonly thought, in Indian culture, to have anti-inflammatory properties that are beneficial for managing diabetes.
In addition to peer review, I ran a controlled comparison by writing my own set of prevention strategies without AI assistance. This allowed me to directly compare the AI-generated content with my findings to assess whether the AI had accurately captured the cultural intricacies of dietary practices among these groups. The comparison revealed that, although the AI provided general dietary advice, it lacked depth in accommodating cultural preferences from diverse population groups.
By integrating this culturally informed feedback and comparison, I was able to make the AI-generated strategies more inclusive and culturally sensitive. The final result provided practical, culturally relevant advice tailored to the dietary practices of each group, ensuring that the educational material was rigorous, credible and free from the biases that the AI might have introduced.
Despite these challenges, I think that it’s crucial to keep pushing forward. AI, in many ways, mirrors our society — its strengths, biases and limitations. As we develop this technology, society needs to be mindful of its technical capabilities and its impact on people and cultures. Looking ahead, I hope the conversation around AI and bias will continue to grow, incorporating more diverse perspectives and ideas. This is an ongoing journey, full of challenges and opportunities. It requires us to stay committed to making AI more inclusive and representative of the diverse world we live in.









.jpg)
















