New research conducted in mice offers insights into what’s going on at the molecular level that could cause people with diabetes to develop Alzheimer’s disease.
The study adds to a growing body of research on the links between Type 2 diabetes and Alzheimer’s disease, which some scientists have called “Type 3 diabetes.” The findings suggest that it should be possible to reduce the risk of Alzheimer’s by keeping diabetes well controlled or avoiding it in the first place, according to researchers.
Narendra Kumar, an associate professor at Texas A&M University in College Station, led the study.
We think that diabetes and Alzheimer’s disease are strongly linked, and by taking preventative or amelioration measures for diabetes, we can prevent or at least significantly slow down the progression of the symptoms of dementia in Alzheimer’s disease.”
Narendra Kumar, Associate Professor, Texas A&M University
Kumar will present the new research at Discover BMB, the annual meeting of the American Society for Biochemistry and Molecular Biology, which is being held March 23–26 in San Antonio.
Diabetes and Alzheimer’s are two of the fastest-growing health concerns worldwide. Diabetes alters the body’s ability to turn food into energy and affects an estimated 1 in 10 U.S. adults. Alzheimer’s, a form of dementia that causes progressive decline in memory and thinking skills, is among the top 10 leading causes of death in the United States.
Diet is known to influence the development of diabetes as well as the severity of its health impacts. To find out how diet could influence the development of Alzheimer’s in people with diabetes, the researchers traced how a particular protein in the gut influences the brain.
They found that a high-fat diet suppresses the expression of the protein, called Jak3, and that mice without this protein experienced a cascade of inflammation starting with the intestine, moving through the liver and on to the brain. Ultimately, the mice showed signs of Alzheimer’s-like symptoms in the brain, including an overexpressed mouse beta-amyloid and hyperphosphorylated tau, as well as evidence of cognitive impairment.
“Liver being the metabolizer for everything we eat, we think that the path from gut to the brain goes through liver,” Kumar said.
His lab has been studying functions of Jak3 for a long time, he added, and they now know that the impact of food on the changes in the expression of Jak3 leads to leaky gut. This in turn results in low-grade chronic inflammation, diabetes, decreased ability of the brain to clear its toxic substances and dementia-like symptoms seen in Alzheimer’s disease.
The good news, according to Kumar, is that it may be possible to stop this inflammatory pathway by eating a healthy diet and getting blood sugar under control as early as possible. In particular, people with prediabetes -; which includes an estimated 98 million U.S. adults -; could benefit from adopting lifestyle changes to reverse prediabetes, prevent the progression to Type 2 diabetes and potentially reduce the risk of Alzheimer’s.
Scientists report they have extracted a compound with powerful antibacterial properties from the skin of farmed African catfish. Although additional testing is necessary to prove the compound is safe and effective for use as future antibiotic, the researchers say it could one day represent a potent new tool against antimicrobial-resistant bacteria such as extended-spectrum beta-lactamase (ESBL) producing E. coli.
Hedmon Okella is a postdoctoral researcher at the University of California, Davis, and led the project.
The global public health threat due to antimicrobial resistance necessitates the search for safe and effective new antibacterial compounds. In this case, fish-derived antimicrobial peptides present a promising source of potential leads.”
Hedmon Okella, postdoctoral researcher, University of California, Davis
Okella will present the new research at Discover BMB, the annual meeting of the American Society for Biochemistry and Molecular Biology, which is being held March 23–26 in San Antonio.
For the study, the researchers extracted several peptides (short chains of amino acids) from African catfish skin mucus and used machine learning algorithms to screen them for potential antibacterial activity. They then chemically synthesized the most promising peptide, called NACAP-II, and tested its efficacy and safety on ESBL-E. coli and mammalian blood cells, respectively.
These tests showed that NACAP-II caused the bacteria to break open, or lyse, without appearing to harm the mammalian blood cells. “Preliminary findings indicate that this promising peptide candidate potentially disrupts the bacterial cell envelope to cause lysis at a very low concentration,” Okella said.
The place where the peptide was found -; in the mucus on the skin of farmed African catfish -; is not as unlikely as it may seem. As anyone who has tried to hold one can attest, fish are enveloped in a slippery layer of mucus. This mucus is known to protect the fish against infections by physically carrying germs off of the skin and by producing antimicrobial compounds such as the one Okella’s team isolated.
Many existing medicines are based on compounds that were first found in nature, and scientists speculate that marine and aquatic organisms represent a particularly rich -; though largely untapped -; source of bioactive compounds.
As a next step, the researchers plan to study the peptide’s effects in animal models and explore strategies to produce it inexpensively.
“We are currently utilizing chemical synthesis to upscale the production of this peptide that we believe will one day be of use as drug candidate in the battle against antimicrobial resistance,” Okella said.
A ‘gene drive’ that spreads through plant populations could be used to wipe out pests such as superweeds, or to help save species by making them resistant to heat or disease
In this new episode of the omg OMx podcast, Kate Stumpo speaks to Chris Taron about his glycobiology experience, mass spectrometry use in the field, and the implications for genetic research. Read selected highlights, or watch the full video below:
Chris Taron | OMG OMx Podcast | Ep. 11
Can you explain how you found your source of innovation and what factors influenced your desire to stay in the workplace even after retiring?
I attribute that to New England Biolabs (NEB), as an organization. They did a remarkable job, specifically Don Comb, in how he originally set up the company with a research-centric focus. It was truly an amazing climate in which to conduct research.
We were engaging with people researching various biochemistry, molecular biology, and enzymology topics. We also attended conferences and interacted with academics and other companies in the field, constantly getting information on the most interesting problems. It was easy to find ideas to work on. There was a climate of collaboration and innovation across the 30 groups working in the company.
We also had the freedom to chase our ideas, which is a significant reason why I stayed with one organization my whole career. I was privately funded to pursue my ideas. It is truly special when you are not burdened with fundraising and grant writing and can instead focus on cutting-edge research, collaborate with academics, publish, and more. This is why many people from NEB have remained as career-long researchers there.
You started your research career in glycobiology and persisted with it for a long time. Can you tell us more about the field and its practical uses?
The first thing we must establish here is a baseline for glycobiology because it is a vast field. Sugars are present in every aspect of cell biology, from nucleic acids to decorations on proteins and lipids. The biology that the glycome influences is incredibly vast because it is everywhere.
My focus within glycobiology has been skewed more toward the applied side. I have been examining enzymes that perform physical actions, acting upon glycans, taking them apart, and constructing them in very specific ways.
When working with enzymes like that, you often use various analytical techniques. So, my journey through glycobiology has been closely tied to the analytical aspects of the field.
I believe there is still tremendous potential and importance going forward in this area. Analytical technologies have significantly improved over the last 20 years. We are now just reaching the point where we can tackle some of the complexities within the glycome because technology has finally caught up with it.
How has mass spectrometry influenced the field of glycobiology? What was the first mass spec experiment you performed, and what was the last thing you did while at NEB?
Early in my career, mass spectrometry was something I never imagined myself doing. I was very interested in biochemistry and genetics, and mass spec was something that only specialized labs did because they had the equipment and the know-how, which was a little frightening for me to look at.
I would put it in the 1990s timeframe. Back then, people were primarily characterizing individual glycoproteins, and they used various types of mass spec depending on the lab doing the work. Different labs had different flavors. I think there has been some convergence over time regarding the types of analyses performed in mass spectrometry.
My first foray into any use of mass spec in my program was in proteomics, not glycomics, and that was in the 2000s, 2010ish. We were starting to identify proteomes that had been secreted from yeast cells and trying to understand the repertoire of glycoproteins that were usually produced so that we could better understand what was contaminating our proteins when we were trying to express, for example, heterologous proteins for a commercial purpose.
From there, we moved on to glycosidases, more glycosidases, and liberated glycan analyses, which led to developing the LC-MS workflows. That is when my lab began to develop its first glycan-based mass spec approaches.
We tiptoed into it. I do not want to say that we were experts in this. We took it slowly through collaborations with people like Pauline Rudd and the National Institute of Bioprocess Research and Training in Dublin, Ireland. Over time, we began to do more of it independently, but we had a lot of help along the way.
As I was nearing the end of my time at NEB, we moved away from liberating glycan analysis from individual proteins and toward true glycomic analysis of entire glycomes. I was also interested in the extracellular matrix, the wild complexity of structures, and using mass spec imaging to visualize that specific environment and the enzymes trying to manipulate it.
Image Credit: Anusorn Nakdee/Shutterstock.com
How do you plan to incorporate protein discovery from a gene-centric perspective now that you are at GMGI? What do you hope to achieve in your new role?
I think that people at GMGI have recognized that, as a genomics-focused organization, there is much they can do. With deep sequencing approaches, scientists have greater access to genomes. But this is only one piece of the puzzle. It is actually what the genes encode that provides a better understanding of biology.
Consider E. coli as an example. I believe the genome for E. coli was first released in ’96 or ’97, which is a long time ago. Nonetheless, 35% of the genes in E. coli are still not functionally defined.
If you go to a space like the ocean and start looking at microbes that have not been discovered yet, from ecological niches that are poorly understood, you start to wonder: What is the genetic makeup? What is the role of proteins in these environments? The potential for discovery is truly enormous.
If you take what you find and start applying it to really good problems, you have a real chance of influencing analytics, improving human health, discovering new therapeutics, and so on.
My next task will be to assemble a world-class screening and protein characterization program that will begin to mine this resource, allowing us to turn it back on some of the old problems.
About the Speaker
Chris is an experienced scientist and research director. He spent most of his career at New England Biolabs (NEB), a leading enzyme and reagent company. Chris performed research for over 33 years on topics in the discovery, expression, biochemical characterization, and biotechnological application of enzymes. At NEB, he directed Protein Expression & Modification research for 18 years. Chris retired from NEB in 2023, but not from science. He recently became the Senior Director of Protein Science & Innovation at the Gloucester Marine Genomics Institute where he leads a new program discovering unique microbial proteins and pathways in diverse marine ecosystems.
omg OMx host: Kate Stumpo, Senior Market Manager at Bruker
Discover new ways to apply mass spectrometry to today’s most pressing analytical challenges. Innovations such as Trapped Ion Mobility (TIMS), smartbeam and scanning lasers for MALDI-MS Imaging that deliver true pixel fidelity, and eXtreme Resolution FTMS (XR) technology capable of revealing Isotopic Fine Structure (IFS) signatures are pushing scientific exploration to new heights. Bruker’s mass spectrometry solutions enable scientists to make breakthrough discoveries and gain deeper insights.
Applying and developing new technologies for DNA synthesis to pave the way for producing entire artificial genomes – that is the goal of a new interdisciplinary center that is being established at Heidelberg University, Karlsruhe Institute of Technology (KIT), and Johannes Gutenberg University Mainz (JGU). The aim of the Center for Synthetic Genomics is to spark new developments in synthetic genomics through basic research and technology development using methods of artificial intelligence. The Carl Zeiss Foundation (CZS) is financing the center’s establishment over a period of six years with a total amount of twelve million euros.
In the long term, it should be possible to design and synthesize long DNA sequences for applications in research, nanomaterials science, and medicine. The first spokesperson of the new center is systems biologist Professor Michael Knop, Deputy Director of the Center for Molecular Biology of Heidelberg University (ZMBH).
While the past two decades of genome research were marked by the development of new genome sequencing techniques, it will become possible to modify genomes more quickly and easily, or even to create entirely new genomes, using innovative methods of DNA synthesis and genome assembly. This is the vision that the Carl Zeiss Foundation Center for Synthetic Genomics Heidelberg – Karlsruhe – Mainz (CZS Center SynGen) will pursue in the coming years. The researchers from the three universities want to design synthetic DNA sequences with the aid of AI-based methods of analysis and modeling in order to make targeted modifications in the genome of organisms and give it new functionalities. The aim is to extract from them so-called biologics, that is, biotechnologically manufactured products. These are eventually to be used to produce bio-based medicines, develop gene therapies for diseases, breed pest-resistant plants, produce biofuels, and advance research into new types of materials.
“At the CZS Centers we consolidate expertise across locations and disciplines. The life sciences in particular require a high degree of interdisciplinary collaboration. At the CZS Center SynGen we aim to advance the production of artificial DNA and tap the immense potential for research, medicine, and beyond,” says Carl Zeiss Foundation Managing Director Dr. Felix Streiter, explaining the motivation for funding the second CZS Center in Germany.
The Center for Synthetic Genomics pools the expertise of three of the leading research institutions, which are now jointly working on an important future-oriented field from basic research to technology development. Our aim is to achieve a wide range of applications in biotechnology, for example in medicine, but also in materials science. We are very pleased to contribute to this with our expertise.”
Professor Oliver Kraft, Acting President of KIT
Synthetic genomics
“Synthetic genomics is a young but rapidly growing research area worldwide, with transfer potential for different socially relevant challenges. In our new center we will pool the complementary expertise of the three strong research universities at Heidelberg, Karlsruhe, and Mainz in the life sciences, molecular systems engineering, and biomedical research. That way, we intend to coordinate all the steps in synthetic genomics, from design and production right up to the application of synthetic genetic materials and organisms,” says Center Spokesperson Michael Knop. “The new center will provide us with a unique opportunity to combine different areas of expertise and disciplines in a new way. Particularly the discourse of biology and medicine with experts in simulation and modeling will show us new ways not only to generate synthetic genomes, but also to better understand and use natural and artificial modifications and epigenetic mechanisms,” Professor Sylvia Erhardt explains. The molecular biologist of Karlsruhe Institute of Technology is a member of the CZS Center SynGen’s three-member Board of Directors alongside Professor Michael Knop and biophysical chemist Professor Edward Lemke of Mainz University.
The Carl Zeiss Foundation Center for Synthetic Genomics Heidelberg – Karlsruhe – Mainz started work in January 2024. Researchers collaborating at the three locations represent different disciplines, including biology, biochemistry, biophysics, biotechnology, synthetic biology, and bioengineering, as well as philosophy and law, genomics, immunology, epigenetics, virology, and data science. In addition, more international experts and early-career researchers are to be recruited to work at the new center. Furthermore, a competence center for the synthesis of synthetic DNA is to be set up in Heidelberg, the so-called CZS Center Synthetic DNA Accelerator Lab. Also involved in the CZS Center SynGen are scientists from the German Cancer Research Center and the Heidelberg Institute for Theoretical Studies, as well as external partners from science and business.
The CZS Center SynGen was officially opened with a festive event held at Heidelberg University on March 4, 2024. In addition to the lead researchers, representatives of the Carl Zeiss Foundation and the participating universities also took part.
Nature, Published online: 06 March 2024; doi:10.1038/d41586-024-00575-x
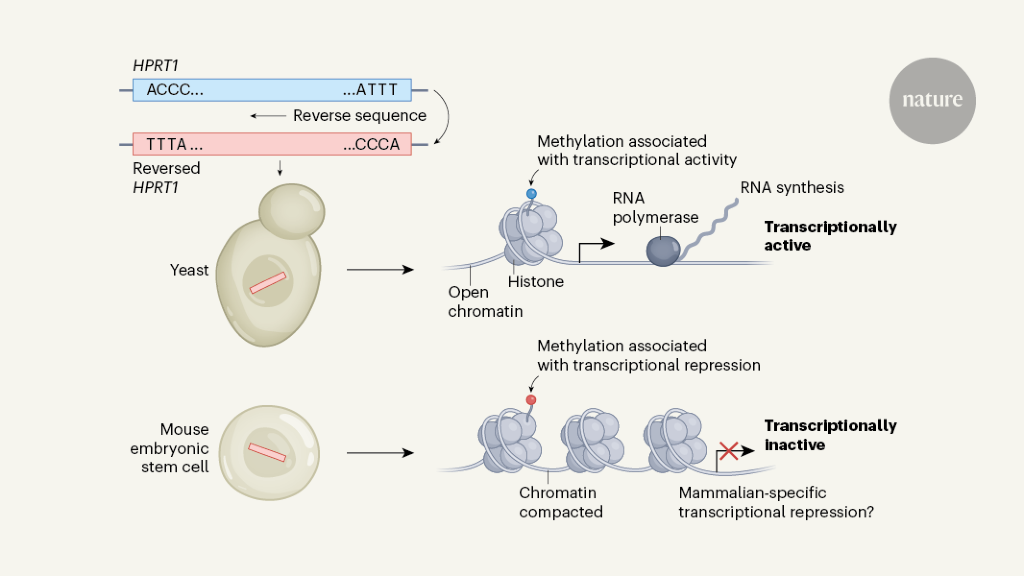
In experiments dubbed the Random Genome Project, researchers have integrated DNA strands with random sequences into yeast and mouse cells to find the default transcriptional state of their genomes.
A new study from a team of McGill University and Vanderbilt University researchers is shedding light on our understanding of the molecular origins of some forms of autism and intellectual disability.
For the first time, researchers were able to successfully capture atomic resolution images of the fast-moving ionotropic glutamate receptor (iGluR) as it transports calcium. iGluRs and their ability to transport calcium are vitally important for many brain functions such as vision or other information coming from sensory organs. Calcium also brings about changes in the signaling capacity of iGluRs and nerve connections which are a key cellular events that lead to our ability to learn new skills and form memories.
iGluRs are also key players in brain development and their dysfunction through genetic mutations has been shown to give rise to some forms of autism and intellectual disability. However, basic questions about how iGluRs trigger biochemical changes in the brain’s physiology by transporting calcium have remained poorly understood.
In the study, the researchers took millions of snapshots of the iGluR protein in the act of transporting calcium, and unexpectedly discovered a temporary pocket that traps calcium on the outside of the protein. With this information at hand, they then used high-resolution electrophysiological recordings to watch the protein in motion as it transported calcium into the nerve cell.
“The results are important because we describe for the first time the mechanism by which calcium is transported, which ultimately drives the cellular processes that lead to learning and memory,” said Derek Bowie, McGill’s lead author of the study, published in Nature Structural and Molecular Biology and co-Director of the Cell Information Systems group in the School of Biomedical Sciences.
The biological mechanism discovered is not only conserved amongst all species of mammals, but is also found in organisms that branched away from the evolutionary pathway of humans more than 500 million years ago.
The original blueprint of the protein design was so good it seems that evolution did not need to change it.”
Derek Bowie, McGill’s lead author of the study
“Visualizing the tiny ions and water molecules in the channel pore using cryo-EM technology was quite an amazing experience. It highlighted an ancient calcium binding pocket which we were able to understand further from a functional perspective in collaboration with Bowie Lab. Our finding is fundamental to calcium signaling in neurons and raises interesting hypotheses about synaptic function that could be tested by experiments in the future,” said Nakagawa, Vanderbilt’s lead author and Professor at the Department of Molecular Physiology and Biophysics at the School of Medicine Basic Sciences.
Source:
Journal reference:
Nakagawa, T., et al. (2024). The open gate of the AMPA receptor forms a Ca2+ binding site critical in regulating ion transport. Nature Structural & Molecular Biology. doi.org/10.1038/s41594-024-01228-3.
The origin of life is one of the greatest challenges in science. It transcends conventional disciplinary boundaries, yet has been approached from within those confines for generations. Not surprisingly, these traditions have emphasized different aspects of the question.
Or rather, questions. The origin of life is really an extended continuum from the simplest prebiotic chemistry to the first reproducing cells, with molecular machines encoded by genes — machines such as ribosomes, the protein-building factories found in all cells. Most scientists agree that these nanomachines are a product of selection — but selection for what, where and how?
There is no consensus about what to look for, or where. Nor is there even agreement on whether all life must be carbon-based — although all known life on Earth is. Did meteorites deliver cells or organic material from outer space? Did life start on Earth in the hot waters of hydrothermal systems on land or in deep seas?
Observations alone cannot constrain these possibilities. The few geological traces that hint at early life are enigmatic. Is a bacterium-like imprint really a fossil, or some geochemical structure? Is a weak carbon isotope signature on the surface of a mineral a fingerprint of life (which accumulates the lighter carbon-12) or the result of another type of chemical activity?
Genes are not directly helpful either. Comparing gene sequences in modern organisms allows researchers to reconstruct a ‘tree of life’ going back to some of the earliest cells that have genes. Although the exact genetic make-up of this ancestral population is disputed, by definition it already had genes and proteins and so can tell us little about how they arose.
How did life begin? One key ingredient is coming into view
None of this precludes understanding the origin of life, but it does make competing hypotheses hard to prove or disprove unambiguously. Combine that with the overarching importance of the question and it’s clear why the field is beset with over-claims and counter-claims, which in turn warp funding, attention and recognition.
This context has splintered the field. Strongly opposed viewpoints have coexisted for decades over basic questions such as the source of energy and carbon, the need for light and whether selection acts on genes, chemical networks or cells.
To understand how life might have begun, researchers must stop cherry-picking the most beautiful bits of data or the most apparently convincing isolated steps, and explore the implications of these deep differences in context. Depending on the starting point, each hypothesis has different testable predictions. For example, if life started in a warm pond on land, the succession of steps leading from prebiotic chemistry to cells with genes is surprisingly different from those that must be posited if the first cells emerged in deep-sea hydrothermal vents.
Building coherent frameworks — in which all the steps in the continuum fit together — is essential to making real progress. To see why, here we highlight two of the most prominent frameworks, which propose radically distinct environments for the origin of life.
Prebiotic soup
Most people have heard of prebiotic soup. That’s in part because the hypothesis is grounded in the chemistry that works best for making many of the building blocks of living things. In the modern version of this idea, the synthesis of organic molecules begins with derivatives of cyanide, energized by ultraviolet radiation. This chemistry can produce relevant products, such as the nucleotide building blocks of genes, in high yields — although different reactions occur in distinct environments, ranging from laboratory equivalents of the atmosphere to geothermal ponds and streams1.
Where did all this cyanide come from? Meteorite impacts might be one source, but there is little agreement about that among geologists. Nor does this approach explain just how these “reservoirs of material … come to life when conditions change”2. That is, how compounds that formed under disparate conditions could persist for long periods (potentially millions of years) before somehow coming together and self-assembling into growing cells.
It’s time to admit that genes are not the blueprint for life
This framework posits that nucleotides are concentrated in a small pond. To form RNA, the simplest and most versatile genetic material, nucleotides must polymerize. That is most easily achieved by drying them out (polymerization is a type of dehydration reaction). Proponents imagine a succession of wet–dry cycles, in which the pond dries out to form polymers of RNA, then fills again with water containing more nucleotides and so on, cycle after cycle, making more and more RNA3.
But this concept raises some difficult questions. It places the onus on an ‘RNA world’, in which RNA acts both as a catalyst (in a similar way to enzymes) and as a genetic template that can be copied. The problems are that there is little evidence that RNA can catalyse many of the reactions attributed to it (such as those required for metabolism); and copying ‘naked’ RNA (that is not enclosed in compartments such as cells) favours the RNA strands that replicate the fastest. Far from building complexity, these tend to get smaller and simpler over time. Worse, by regularly drying everything out, wet–dry cycles keep forming random groupings of RNA (in effect, randomized genomes). The best combinations, which happen to encode multiple useful catalysts, are immediately lost again by re-randomization in the next generation, precluding the ‘vertical inheritance’ that is needed for evolution to build novelty.
If selection on RNA in drying ponds could somehow be made to generate greater complexity, what must it achieve? To make cells that grow and reproduce, RNA must encode metabolism: the network of hundreds of reactions that keeps all cells alive. Modern-day metabolic reactions bear no resemblance to the cyanide chemistry that makes nucleotides in this model. Evolution would therefore need to replace each and every step in metabolism, and there is no evidence that such a wholesale replacement is possible.
Unlike evolving an eye, a process in which intermediates have function, encoding only half the steps of a metabolic pathway (or half the pathways needed for a free-living cell) has little, if any, benefit. Can genes that encode multiple metabolic pathways have arisen at once? The odds against this are so great that the astrophysicist Fred Hoyle once compared it to a tornado blowing through a junkyard and assembling a jumbo jet. It is not good enough to counter that evolution will find a way: a real explanation needs to specify how.
On balance, we would say that prebiotic chemistry starting with cyanide can produce the building blocks of life, but most of the downstream steps predicted by this framework remain problematic.
Hydrothermal systems
Our own favoured scenario is that the chemistry of life reflects the conditions under which life began, in deep-sea hydrothermal systems on the early Earth4. In broad brush strokes, this means that gases such as carbon dioxide (the near-universal source of carbon in cells today) and hydrogen feed a network of reactions with a topology resembling metabolism. Genes and proteins arise within this spontaneous protometabolism and promote the flux of materials through the network, leading to cell growth and reproduction. There are plenty of problems here, too, but they differ from those in the prebiotic soup framework.
Origin of life theory involving RNA–protein hybrid gets new support
The first problem is that H2 and CO2 are not particularly reactive — indeed, their chemistry was largely ignored for decades, although rising interest in green chemistry is changing that. But deep-sea vents are labyrinths of interconnected pores, which have a topology resembling cells — acidic outside and alkaline inside. The flow of protons from the outside to the inside of these pores can drive work in much the same way that the inward flow of protons can drive CO2 fixation in cells today5. Research in the past few years shows that these conditions can drive the synthesis of carboxylic acids6 and long-chain fatty acids7, which can self-assemble into cell-like structures bounded by lipid bilayer membranes5.
But many chemists are troubled by the idea that, in the absence of enzymes to serve as catalysts, hydrothermal flow could drive scores of reactions through a network that prefigures metabolism, from CO2 right up to nucleotides. The chemist Leslie Orgel once dismissed this scenario as an “appeal to magic”. Certainly, further data are required, supporting or otherwise. Multiple steps have now been shown to occur spontaneously in core metabolic pathways (such as the Krebs cycle and amino-acid biosynthesis) without being driven by enzymes8, but this is still far from demonstrating flux through the entire network.
Polymerization is another stumbling block. Nucleotides have been polymerized in water on mineral surfaces9, but this raises similar questions to those noted for wet–dry cycles about how selection could act. If the problem is solved by polymerizing nucleotides inside growing protocells, mineral surfaces would not have been available. Polymerization would then have needed to happen in cell-like (aqueous gel) conditions, but without enzymes. If serious attempts to synthesize RNA under those conditions fail, the overall framework would need to be modified.
A 13-metre-tall carbonate chimney in the Lost City hydrothermal field in the Atlantic Ocean.Credit: Deborah Kelley and Mitch Elend, University of Washington
Conversely, if these difficult problems are resolved, then the hydrothermal scenario offers a promising route to the emergence of genetic information, overcoming Hoyle’s jumbo-jet argument. Patterns in the genetic code suggest direct physical interactions between amino acids and the nucleotides that encode them, especially for those formed most easily by metabolism5. Such associations mean that random RNA sequences could act as templates for non-random peptides that have a function in growing protocells. The first genes wouldn’t have had to encode metabolism, but just enhance flux through a spontaneous protometabolism — for example, by enabling the reaction between H2 and CO2.
Thus, in short, the two frameworks have different advantages and disadvantages, and it is premature to dismiss either.
Findings can be true but irrelevant
Similarly probing questions apply to other origins-of-life scenarios. If organic molecules were delivered from space — for instance, in carbonaceous chondrites such as the Murchison meteorite10 — then how and where did they come together, how did they polymerize, and so on? The delivery of organics from space simply stocks a soup and doesn’t solve most of the downstream problems — with the further issue that such a delivery method is unlikely to have been reliable and consistent at specific locations.
If life started out as droplets known as coacervates, in which immiscible liquids separate into distinct phases that promote different types of chemistry, then one must ask where all the precursors to feed their growth came from. And how did these phase-separated droplets morph into cells with different topology, in which these distinct chemistries now mostly occur under aqueous-gel conditions?
Prebiotic chemistry
Similar questions can be asked about ‘eutectic freezing’ (in which growing ice crystals concentrate the surrounding soup) and layered minerals or pores in volcanic rocks, such as basalt or floating pumice, that catalyse organic synthesis.
All of these fragments of scenarios are ‘true’, in that there is empirical evidence supporting each snapshot moment. But the fact that it is possible to make amino acids by passing electrical discharges through a Jovian mixture of gases, as the US chemist Stanley Miller famously did 70 years ago, does not mean that is how life began — merely that this chemistry is possible. Likewise, the fact that analogous chemistry can occur in hydrothermal systems, or from cyanide in terrestrial geothermal systems, or in interstellar space, does not mean that all of these environments were required for life to start, just that this chemistry is favoured under many conditions. The question is always: what happens next?
If none of these scenarios is ‘wrong’, then there is space in the field to pursue multiple frameworks. No one needs to abandon their favoured positions (yet). But brash claims for a breakthrough on the origin of life are unhelpful noise if they do not come in the context of a wider framework. The problem is ultimately answerable only if the whole question is taken seriously.
Look for convergence points
An important feature of these competing frameworks is that they must ultimately converge on cells with genes and proteins — on life as we know it on Earth. This convergence offers new possibilities for collaboration, because any answer will probably feature aspects of more than one framework. Exactly where these convergences occur will depend on which hypothetical steps are disproved.
Cofactors offer a possible convergence point. They got their name because they work together with an enzyme to catalyse a reaction. But from an origins-of-life perspective, the term is misleading because cofactors usually catalyse the same reaction on their own, albeit more slowly. Many cofactors derive from nucleotides, such as nicotinamide adenine dinucleotide. These might prove hard to make when starting with CO2. Could it be that cofactors were initially synthesized from cyanide, but, once in circulation, tended to catalyse CO2 chemistry, now driving a lifelike protometabolism that included their own synthesis11?
Bringing space rocks back to Earth could answer some of life’s biggest questions
Perhaps, but this idea also shows how important it is to test predictions within a specific framework first. In the simplest scenario, all of biochemistry begins from CO2 in a hydrothermal system, whereas the alternative scenario calls for at least two places and two types of chemistry — adding up to much more uncertainty. Occam’s razor says that the simplest scenario should be tested thoroughly first. If the simplest chemistry is shown not to work — that is, if it is not possible to synthesize cofactors from CO2 without cofactors — then the alternative can be taken seriously.
This question could be approached experimentally or using modern computational chemistry tools, but either way, the best way to make progress is to test the simplest idea to destruction first. If it can be shown not to work, then the convergence point might be real, and should be explored seriously.
Towards an answer
The origins-of-life field faces the same problems with culture and incentives that afflict all of science — overselling ideas towards publication and funding, too little common ground between competing groups and perhaps too much pride: too strong an attachment to favoured scenarios, and too little willingness to be proved wrong. These incentives are amplified by the difficulty of disproving complex interrelated hypotheses involving different disciplines when there is so little direct evidence — no ‘smoking gun’ to be discovered.
Changing this culture will take some work, given the political reality of science — the relentless pressure to publish, to secure funding, tenure or promotion — but it is necessary if the field wishes to continue attracting students. This requires that scientists, but also editors and funders, are aware of the issues that fragmented the field and work to overcome them. We highlight four priorities to begin to move in the right direction.
Train interdisciplinary scientists. Pursuing hypotheses across conventional disciplinary boundaries calls for a new generation of scientists — PhD students, postdoctoral researchers and early-career principal investigators (PIs) — with wide-ranging expertise and a willingness to test specific hypotheses within coherent wider frameworks. The field will clearly benefit from doctoral training that stresses collegiality, interdisciplinarity and the rigorous, open-minded testing of competing hypotheses.
Foster good communication. To promote such a culture, one of us (J.C.X.) co-founded the Origin of Life Early-career Network (OoLEN) in 2020, which has grown to more than 200 international researchers, from students to early-career PIs. It is run by volunteers and has no institutional ties, financial or otherwise. Members engage in debates through regular meetings (online or in-person), disseminate research and write articles together. There is still no shortage of disagreements, but that is part of scientific research and OoLEN promotes a healthy approach to them12.
For later-career researchers, conferences could help to reach across divides in similar ways. Physics meetings have provided examples. In one, proponents of loop quantum gravity and string theory switched sides in a debate, framing good-humoured but strong arguments against their own position in a constructive form of ‘steel manning’.
Embrace open science. Accepting that specific hypotheses will be disproved and that frameworks will be reshaped requires the publication of negative results — too often undervalued and unpublished. But it is clearly important for the field to know whether, for example, attempts to synthesize cofactors from CO2 fail — and, specifically, under what conditions.
Dissemination of negative data could be promoted in several ways. Most valuable is a more systematic use of open-access, community-driven knowledge bases that would host and curate data. These would help to collate experimental conditions, highlight genuine gaps in empirical evidence and enable analysis of large data sets through machine-learning studies.
Improve publishing practices. Researchers should aspire to contextualize their findings in cover letters, papers and press releases, to give a sense of how the work fits into a wider framework. Refraining from hype might seem unrealistic but could work if researchers implemented this practice in their roles as peer reviewers for papers and grants as well as authors.
Journal editors and grant-awarding bodies should also consider how polarized the field is to ensure fair reviews. One way to improve the peer-review process would be to enlist more early-career researchers, who tend to be less entrenched in their positions. Transparent peer review (in which anonymous reports are published with a paper) could also curb bias, because it enables constructive criticism without concealing prejudice.
It is too soon to aim for consensus or unity, and the question is too big; the field needs constructive disunity. Embracing multiple rigorous frameworks for the origin of life, as we advocate here, will promote objectivity, cooperation and falsifiability — good science — while still enabling researchers to focus on what they care most about. Without that, science loses its sparkle and creativity, never more important than here. With it, the field might one day get close to an answer.
Scientists have long believed that a newborn’s immune system was an immature version of an adult’s, but new research from Cornell University shows that newborns’ T cells – white blood cells that protect from disease – outperform those of adults at fighting off numerous infections.
These results help clarify why adults and infants respond differently to infections and pave the way for controlling T cells’ behavior for therapeutic applications.
This discovery was described in a paper published in Science Immunology on Feb. 23, co-led by Brian Rudd, associate professor of microbiology and immunology, and Andrew Grimson, professor of molecular biology and genetics.
For example, adult T cells outperform newborn T cells at tasks including recognizing antigens, forming immunological memory and responding to repeat infections, which has led to the belief that infant’s T cells were just a weaker version of the adult ones. But during the COVID-19 pandemic, many were surprised by the apparent lack of illness in infants, bringing this long-standing belief into question.
Interested in understanding these age-related differences, Rudd and Grimson discovered that newborn T cells are not deficient: Instead, they are involved in a part of the immune system that does not require antigen recognition: the innate arm of the immune system. While adults T cells use adaptive immunity – recognizing specific germs to then fight them later – newborn T cells are activated by proteins associated with innate immunity, the part of the immune system that offers rapid but nonspecific protection against microbes the body has never encountered.
Our paper demonstrates that neonatal T cells are not impaired, they are just different than adult T cells and these differences likely reflect the type of functions that are most useful to the host at distinct stages of life.”
Brian Rudd, associate professor of microbiology and immunology, Cornell University
Neonatal T cells can participate in the innate arm of the immune system. This enables newborn T cells to do something that most adult T cells cannot: respond during the very first stages of an infection and defend against a wide variety of unknown bacteria, parasites and viruses.
“We know that neonatal T cells don’t protect as well as adult T cells against repeat infections with the same pathogen. But neonatal T cells actually have an enhanced ability to protect the host against early stages of an initial infection,” Rudd said. “So, it is not possible to say adult T cells are better than neonatal T cells or neonatal T cells are better than adult T cells. They just have different functions.”
Following up on his discovery, Rudd wants to study the neonatal T cells that persist into adulthood in humans. “We are also interested in studying how changes in the relative numbers of neonatal T cells in adults contributes to variation in the susceptibility to infection and outcomes to disease,” he said.
This work was supported by the National Institute of Allergy and Infectious Disease and the National Institute of Child Health and Human Development, in the National Institutes of Health.
Source:
Journal reference:
Watson, N. B., et al. (2024) The gene regulatory basis of bystander activation in CD8+ T cells. Science Immunology.doi.org/10.1126/sciimmunol.adf8776.
Tabak, H. F., Van der Horst, G., Osinga, K. A. & Arnberg, A. C. Splicing of large ribosomal precursor RNA and processing of intron RNA in yeast mitochondria. Cell39, 623–629 (1984).
Grabowski, P. J., Zaug, A. J. & Cech, T. R. The intervening sequence of the ribosomal RNA precursor is converted to a circular RNA in isolated nuclei of Tetrahymena. Cell23, 467–476 (1981).
Sanger, H. L., Klotz, G., Riesner, D., Gross, H. J. & Kleinschmidt, A. K. Viroids are single-stranded covalently closed circular RNA molecules existing as highly base-paired rod-like structures. Proc. Natl Acad. Sci. USA73, 3852–3856 (1976).
Salzman, J., Gawad, C., Wang, P. L., Lacayo, N. & Brown, P. O. Circular RNAs are the predominant transcript isoform from hundreds of human genes in diverse cell types. PLoS ONE7, e30733 (2012).
Westholm, J. O. et al. Genome-wide analysis of Drosophila circular RNAs reveals their structural and sequence properties and age-dependent neural accumulation. Cell Rep.9, 1966–1980 (2014).
Wickramasinghe, V. O. et al. Selective nuclear export of specific classes of mRNA from mammalian nuclei is promoted by GANP. Nucleic Acids Res.42, 5059–5071 (2014).
Wickramasinghe, V. O. et al. Human inositol polyphosphate multikinase regulates transcript-selective nuclear mRNA export to preserve genome integrity. Mol. Cell51, 737–750 (2013).
Jani, D. et al. Functional and structural characterization of the mammalian TREX-2 complex that links transcription with nuclear messenger RNA export. Nucleic Acids Res.40, 4562–4573 (2012).
Huang, C., Liang, D., Tatomer, D. C. & Wilusz, J. E. A length-dependent evolutionarily conserved pathway controls nuclear export of circular RNAs. Genes Dev.32, 639–644 (2018).
Rouquette, J., Choesmel, V. & Gleizes, P. E. Nuclear export and cytoplasmic processing of precursors to the 40S ribosomal subunits in mammalian cells. EMBO J.24, 2862–2872 (2005).
Ohno, M., Segref, A., Bachi, A., Wilm, M. & Mattaj, I. W. PHAX, a mediator of U snRNA nuclear export whose activity is regulated by phosphorylation. Cell101, 187–198 (2000).
Lapalombella, R. et al. Selective inhibitors of nuclear export show that CRM1/XPO1 is a target in chronic lymphocytic leukemia. Blood120, 4621–4634 (2012).
Kelley, J. B. & Paschal, B. M. Hyperosmotic stress signaling to the nucleus disrupts the Ran gradient and the production of RanGTP. Mol. Biol. Cell18, 4365–4376 (2007).
Klebe, C., Bischoff, F. R., Ponstingl, H. & Wittinghofer, A. Interaction of the nuclear GTP-binding protein Ran with its regulatory proteins RCC1 and RanGAP1. Biochemistry34, 639–647 (1995).
Kutay, U., Bischoff, F. R., Kostka, S., Kraft, R. & Gorlich, D. Export of importin α from the nucleus is mediated by a specific nuclear transport factor. Cell90, 1061–1071 (1997).
Enuka, Y. et al. Circular RNAs are long-lived and display only minimal early alterations in response to a growth factor. Nucleic Acids Res.44, 1370–1383 (2016).
Degrauwe, N., Suva, M. L., Janiszewska, M., Riggi, N. & Stamenkovic, I. IMPs: an RNA-binding protein family that provides a link between stem cell maintenance in normal development and cancer. Genes Dev.30, 2459–2474 (2016).
Conway, A. E. et al. Enhanced CLIP uncovers IMP protein-RNA targets in human pluripotent stem cells important for cell adhesion and survival. Cell Rep.15, 666–679 (2016).
Priest, L., Peters, J. S. & Kukura, P. Scattering-based light microscopy: from metal nanoparticles to single proteins. Chem. Rev.121, 11937–11970 (2021).
Kornbluth, S., Dasso, M. & Newport, J. Evidence for a dual role for TC4 protein in regulating nuclear structure and cell cycle progression. J. Cell Biol.125, 705–719 (1994).
Thorvaldsdottir, H., Robinson, J. T. & Mesirov, J. P. Integrative Genomics Viewer (IGV): high-performance genomics data visualization and exploration. Brief. Bioinform.14, 178–192 (2013).
Berger, I., Fitzgerald, D. J. & Richmond, T. J. Baculovirus expression system for heterologous multiprotein complexes. Nat. Biotechnol.22, 1583–1587 (2004).
Pillman, K. A. et al. miR-200/375 control epithelial plasticity-associated alternative splicing by repressing the RNA-binding protein Quaking. EMBO J.37, e99016 (2018).
Gasteiger, E. et al. in The Proteomics Protocols Handbook (ed. Walker, J. M.) 571–607 (Humana Press, 2005).
Fernandes, R. C. et al. Post-transcriptional gene regulation by microRNA-194 promotes neuroendocrine transdifferentiation in prostate cancer. Cell Rep.34, 108585 (2021).