Neuroscience has undergone remarkable progress. Researchers can now study specific areas of the brain with unprecedented detail thanks to cutting-edge imaging and genetic tools. Advanced modelling techniques, driven by artificial intelligence, have facilitated whole-brain mapping to track cognitive development over a lifetime. But fundamental questions about how the brain’s core functions emerge from cellular and molecular processes remain unanswered, limiting treatment options for neurological conditions.
Nature Index 2024 Neuroscience
Countries are pooling their resources and expertise to up the ante. Large-scale neuroscience projects are making use of unique strengths, including China’s vast population data and the United States’ med-tech industry. But researchers are calling for more funding, pointing out that budgets in other areas, such as the European particle-physics laboratory, CERN, and NASA’s James Webb Space Telescope, dwarf those of the biggest neuroscience initiatives.
Raising more money is not the only challenge. Over the past decade, tens of billions have been spent on finding effective treatments for Alzheimer’s disease, with limited patient benefit. A greater understanding of how brain conditions relate to other organs and biological systems, and vice versa, is needed. Studies investigating long COVID, for instance, could have major implications for autoimmune diseases.
In the coming years, technological advances such as implantable brain–computer interfaces (BCIs) are expected to fundamentally change how neuroscience is researched, and how neurological disorders are treated and diagnosed. The United States, the leading country in Nature Index neuroscience output by some margin, is setting the pace for BCI regulation, and other nations will need to find their footing fast.
The Carbon Neutral Laboratory at the University of Nottingham, UK, consumes less than 40% of the power used by a typical lab of similar size.Credit: Martine Hamilton Knight Photography
As chief executive of My Green Lab, a non-profit organization in San Diego, California, James Connelly pays close attention to the marketing claims on scientific equipment and products: “Ultra efficient.” “Low impact.” “Renewable.”
Such words might offer comfort to scientists who are concerned about sustainability, but not every product lives up to the billing. “For some reason, it’s been seen as acceptable in the science industry for a company to go out and put a green leaf on their product without having any real meaning, verification or validation,” Connelly says.
Nature Spotlight: Green laboratories
Researchers are increasingly showing interest in sustainability, says Joanne Durgan, a cell biologist at the Babraham Institute in Cambridge, UK. After all, they are uniquely qualified to understand the various threats to the planet. “As a scientist, I’m used to collecting and analysing data, and that helped me see the scale and the urgency of the problem,” she says. “But it’s a bit out of our field to understand the best choices to make.” If scientists really want to reduce their environmental impact, she says, they’ll need to take an approach that’s as evidence-based and results-oriented as their research.
A 2024 report in the journal RSC Sustainability laid out some eye-opening statistics: at a typical university, research laboratories account for at least 60% of the energy and water use1. And, depending on their field of study, researchers have a work-related carbon footprint that is 7–25 times greater than the per-person climate-maintenance guideline set out in the Paris agreement.
“Most of the scientists that I work with are pretty well informed on environmental issues and are broadly keen to do the right thing,” says Durgan. “It’s maybe just hard to understand the best way to manage that impact.”
Embracing sustainable solutions
In some sectors, this awareness is turning into action, says Thomas Freese, the lead author of the RSC Sustainability report1 and a PhD student in green chemistry at the University of Groningen in the Netherlands. Leading research universities are cutting their environmental impact, funders are raising their standards and individual scientists are changing their protocols to make their research more efficient, less wasteful and more sustainable. “It’s an intellectual grassroots movement,” Freese says.
Durgan is one of a growing number of researchers who are trying to deliver the message that science can be more sustainable without compromising the scope or quality of the results. At the Babraham Institute, she chairs the steering committee for the Green Labs Initiative, a cross-disciplinary effort to reduce the planetary impact of research across the campus. As part of that, the institute retrofitted its heavily used autoclaves with a system that uses recirculated water, saving about 32,000 litres of water each week2.
To spread the word, Durgan and her co-authors laid out a plan of action for scientists who want to limit their environmental impact2. Much of the advice is geared towards lab-based researchers, but the team emphasizes that sustainability can be an issue in just about any field of science, including those in which most of the work happens on a computer. Astronomers, for example, have some of the largest annual carbon footprints in all of the sciences — up to 37 tonnes of carbon dioxide equivalent emissions per researcher1 — mostly because of the energy needed to run the supercomputers they rely on for research.
Some steps can be as simple as pushing a few buttons. Durgan explains that the Babraham’s labs turned the temperature of their 40 ultra-cold freezers up, from −80 °C to −70 °C . Some researchers warned that, if the freezers ever malfunctioned, the samples would spoil faster without that extra 10 °C cushion. To ease those concerns, Durgan spoke to Martin Howes, then the sustainable-labs coordinator at the University of Cambridge, UK, who reported that scientists there had made the adjustment without any issues. She was also reassured by the roster of researchers who reported their own experiences with −70 °C freezers to My Green Lab (see go.nature.com/3xtbeen). At the Babraham, the move reduced energy consumption by nearly 20% without affecting the frozen samples.
Cell biologist Joanne Durgan led an initiative to turn up the temperature of ultra-cold freezers to save energy at the Babraham Institute in Cambridge, UK.Credit: Joanne Durgan/ Babraham Institute
Fume hoods are also prime targets in energy-conservation efforts. As outlined in the RSC Sustainability report, a typical fume hood uses 3.5 times more energy than an average household does each year1. Harvard University in Cambridge, Massachusetts, has estimated that it costs more than US$4,500 to run a fume hood per year, a significant dent to a lab’s budget. Simply closing the sliding window at the front of the hood when not working on an experiment can cut the airflow rate by two-thirds, with similar reductions in energy expenditure1. A Harvard initiative in 2015–16 to close fume hoods reduced energy costs by nearly $200,000 each year3.
Durgan warns that other steps aren’t always so obvious or clear-cut. “You might think about trading some plastic items for reusable glassware,” she says. “But that’s going to use water, and it’s going to require energy to sterilize the glass.”
Durgan adds that any cutbacks in the name of sustainability could lead to more waste if the research results aren’t reliable. “The more effort we make to be sure that our data is robust and reproducible, the less collective time and resources are going to be wasted by the international research community trying to chase or follow up those findings,” she says.
Unfortunately, Connelly says, scientists can’t simply consult manufacturers’ labels to determine which products deliver efficiency without compromising research results. In a practice known as greenwashing, firms can attach claims of sustainability to truly wasteful products. “Companies are using their own standards,” Connelly said. “Without third-party verification, you have to be smart enough to know which standards are credible and which ones aren’t.”
Backing the movement
In a bid to improve clarity, My Green Lab has created ACT (accountability, consistency, transparency), a database of independently generated environmental-impact scores for more than 1,200 lab supplies, from pipettes and solvents to freezers and mass spectrometers. The scores, presented on a branded ACT label, take into account the full life cycle of a product, including its manufacturing impact, use of energy and water, packaging and ultimate disposal.
My Green Lab also offers a road map to scientific sustainability through a certification programme that requires labs to meet certain standards and benchmarks on the use of energy, water and supplies. Those that want to go through the process have to submit an application and pay a fee, currently $500 for academic labs and $4,000 for commercial labs. So far, around 1,200 labs in 47 countries have been certified. Not all will qualify for certification, but successful applicants are awarded a wall plaque. Certification lasts for two years; if a lab wants to remain certified after that, it has to go through the process again.
“These types of programme have value beyond the cost of the certification,” says Davida Smyth, a microbiologist at Texas A&M University in San Antonio who co-authored a 2020 paper on the challenges of making research labs more sustainable4. Certification “sends a signal to your colleagues, other labs, your students, the institution and beyond. This must be a communal effort”.
Plaques, stickers and other forms of recognition can be meaningful, but science might need a stronger incentive structure to attract more labs to the movement, Durgan says. She applauds the Concordat for the Environmental Sustainability of Research and Innovation Practice, released in April by Wellcome in London, the largest UK charity in terms of expenditure and a major funder of biomedical science worldwide (see go.nature.com/4d4dpqs). By the end of 2025, Wellcome will only fund labs that have received some level of accreditation, such as from My Green Labs or LEAF (Laboratory Efficiency Assessment Framework), a programme at University College London (see go.nature.com/4etcnwe). Likewise, Cancer Research UK — which has set a goal to reduce its direct and indirect carbon emissions by 50% by 2030 — will require that all funding applicants be LEAF-certified by 2026.
Funding agencies are really the only entities that can bring large-scale change, Durgan says. “People who might not have been so motivated from an environmental perspective will now have a strategic reason to be more sustainable, because funding is going to depend on it.”
PhD student Thomas Freese at the University of Groningen says his institution has saved more than $440,000 each year by adopting energy-efficiency measures.Credit: Henk Veenstra/ARC CBBC
Connelly applauds Wellcome’s move to require certification, but he thinks that other agencies, such as the US National Institutes of Health (NIH), need to follow suit in the drive for sustainable science. In the United States, the NIH is “the elephant in the room”, he says, noting the agency’s massive influence on biomedical research in the country. “We need leadership from that institution to drive change through the broader academic industry.”
In a statement to Nature, the NIH Office of Extramural Research said it doesn’t require lab certification, but does “consider the scientific environment during peer review and monitor compliance with all requirements post-award through our grants oversight procedures”.
Cost savings can also serve as an incentive. Freese says that at the University of Groningen, the 46 labs that received LEAF certification saw total cost savings of more than $440,000 each year — an average of more than $9,500 per lab — by adopting energy-saving measures that required minimal investment.
Individual labs have reported even more impressive results. In 2022, Jane Kilcoyne, a research chemist at the Marine Institute in Galway, Ireland, achieved annual savings of $16,000 by, among other things, turning up the temperature of freezers, closing fume hoods when possible, and ordering and preparing solutions and reagents only as needed (see Nature https://doi.org/nhhm; 2022).
Future visions
Despite some setbacks, sustainability is also leading to savings for the Carbon Neutral Laboratory, a one-of-a-kind facility at the University of Nottingham, UK. The lab officially opened in 2017 at a reported cost of $20.8 million, with most of the funding coming from the multinational pharmaceutical company GSK. The building, powered partly by solar arrays and a biofuel heat system, is designed to consume less than 40% of the power used by a typical lab of a similar size. “We’re paying back the carbon [used for construction] by not buying electricity from the grid,” says chemist Peter Licence, director of the lab. “The whole concept is an experiment.”
Still, it will take some time for the lab to live up to its name. The original aspiration was to reach net carbon neutrality within 25 years, enough time to allow energy savings to offset the energy required for its construction. “We are, at the moment, slightly behind target because there’s been some technical problems with some of the mechanical, electrical and combined heat and power units that are run on biomass,” Licence says. “I’m fairly confident that we will achieve carbon neutrality by the 25-year time frame. But where we sit right now, I would say that we’re probably three, four or five years behind that payback schedule.”
He says the Carbon Neutral Laboratory has found efficiencies through collaboration. “We share a lot of things like fume hoods and spectrometers,” says Licence. Sharing takes more planning and patience, but helps to save energy and space while promoting conversation and collaboration. “The entire building is designed to make people think differently. Students and academics share ideas, work together and often translate knowledge in a much more rapid and much less siloed way than we would have in a traditional old-school chemistry department.”
Scientists at the Carbon Neutral Laboratory are encouraged to reduce their use of highly toxic solvents, including chemicals that have been part of standard protocols for decades. “If a reaction that I want to do requires me to use dichloromethane, I will then challenge myself to look for an alternative,” Licence says.
But researchers are never asked to scale back their ambitions or to limit their reach in the name of sustainability, he says. “The science speaks for itself,” he says. “It just so happens that we executed that science in the world’s most sustainable chemistry laboratory.”
Before scientists make any changes to their protocols, they should be confident that their results won’t be affected. “If your research requires you to use 20 litres of solvent or 20 pipette tips, you should absolutely do that,” Freese says. “You should not feel bad about conducting more experiments if it means your results become more significant and reproducible.”
Many scientists could reduce their environmental impact by rethinking their approach to planning and executing experiments, Durgan says. With more careful planning and forethought, they could cut down on redundant tests or experiments, a move that would save money and time as well as energy and resources. “Being as critical as you can be about what experiment you choose to do and how you choose to do it at the front end is just a good way to do your science anyway.”
Researchers built an artificial intelligence tool that came up with 4000 novel research ideas in a matter of hours. Credit: Malte Mueller/Getty
An ideas generator powered by artificial intelligence (AI) came up with more original research ideas than did 50 scientists working independently, according to a preprint posted on arXiv this month1.
The human and AI-generated ideas were evaluated by reviewers, who were not told who or what had created each idea. The reviewers scored AI-generated concepts as more exciting than those written by humans, although the AI’s suggestions scored slightly lower on feasibility.
But scientists note the study, which has not been peer-reviewed, has limitations. It focused on one area of research and required human participants to come up with ideas on the fly, which probably hindered their ability to produce their best concepts.
AI in science
There are burgeoning efforts to explore how LLMs can be used to automate research tasks, including writing papers, generating code and searching literature. But it’s been difficult to assess whether these AI tools can generate fresh research angles at a level similar to that of humans. That’s because evaluating ideas is highly subjective and requires gathering researchers who have the expertise to assess them carefully, says study co-author, Chenglei Si. “The best way for us to contextualise such capabilities is to have a head-to-head comparison,” says Si, a computer scientist at Stanford University in California.
The year-long project is one of the biggest efforts to assess whether large language models (LLMs) — the technology underlying tools such as ChatGPT — can produce innovative research ideas, says Tom Hope, a computer scientist at the Allen Institute for AI in Jerusalem. “More work like this needs to be done,” he says.
The team recruited more than 100 researchers in natural language processing — a branch of computer science that focuses on communication between AI and humans. Forty-nine participants were tasked with developing and writing ideas, based on one of seven topics, within ten days. As an incentive, the researchers paid the participants US$300 for each idea, with a $1,000 bonus for the five top-scoring ideas.
Meanwhile, the researchers built an idea generator using Claude 3.5, an LLM developed by Anthropic in San Francisco, California. The researchers prompted their AI tool to find papers relevant to the seven research topics using Semantic Scholar, an AI-powered literature-search engine. On the basis of these papers, the researchers then prompted their AI agent to generate 4,000 ideas on each research topic and instructed it to rank the most original ones.
Human reviewers
Next, the researchers randomly assigned the human- and AI-generated ideas to 79 reviewers, who scored each idea on its novelty, excitement, feasibility and expected effectiveness. To ensure that the ideas’ creators remained unknown to the reviewers, the researchers used another LLM to edit both types of text to standardize the writing style and tone without changing the ideas themselves.
On average, the reviewers scored the AI-generated ideas as more original and exciting than those written by human participants. However, when the team took a closer look at the 4,000 LLM-produced ideas, they found only around 200 that were truly unique, suggesting that the AI became less original as it churned out ideas.
When Si surveyed the participants, most admitted that their submitted ideas were average compared with those they had produced in the past.
The results suggest that LLMs might be able to produce ideas that are slightly more original than those in the existing literature, says Cong Lu, a machine-learning researcher at the University of British Columbia in Vancouver, Canada. But whether they can beat the most groundbreaking human ideas is an open question.
Another limitation is that the study compared written ideas that had been edited by an LLM, which altered the language and length of the submissions, says Jevin West, a computational social scientist at the University of Washington in Seattle. Such changes could have subtly influenced how reviewers perceived novelty, he says. West adds that pitting researchers against an LLM that can generate thousands of ideas in hours might not make for a totally fair comparison. “You have to compare apples to apples,” he says.
Si and his colleagues are planning to compare AI-generated ideas with leading conference papers to gain a better understanding of how LLMs stack up against human creativity. “We are trying to push the community to think harder about how the future should look when AI can take on a more active role in the research process,” he says.
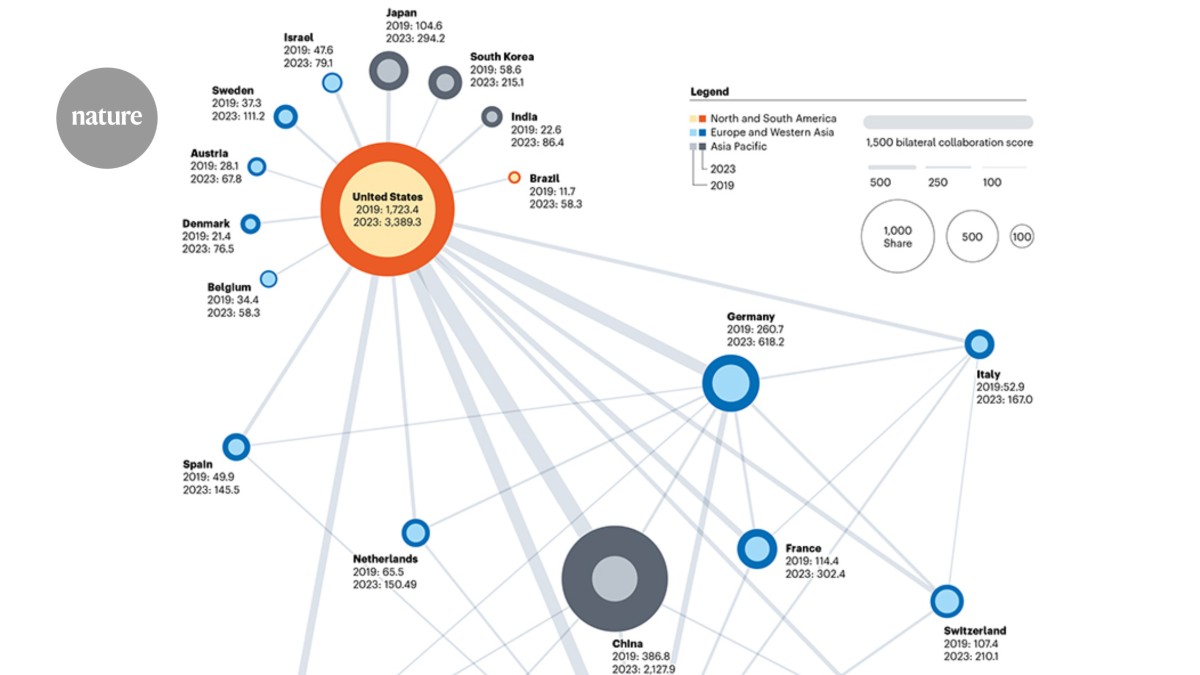
The United States is key to many of the top 40 international collaborations in Nature Index artificial intelligence (AI) research, as measured by their bilateral collaboration score. But there is evidence that other countries are also nodes of activity, including the United Kingdom and Germany. China’s individual AI research output in the database has risen quickly, but it is relatively decoupled from global networks.
The United Kingdom in particular seems to have built a strong network, with more connections among the top 40 bilateral international collaborations in AI than some bigger nations such as China. Canada is also a relatively strong player in AI research collaborations, being involved in four of the top 40 country pairings.
Source: Nature Index. Data analysis by Aayush Kagathra. Data visualization by Simon Baker and Tanner Maxwell.
The United States has built strong bilateral research collaborations with countries that have important connections of their own. But there is also a number of nations that have a strong AI research partnership with the United States, but no other bilateral collaborations in the top 40. These include nations that are, individually, big hitters in AI research such as Japan, South Korea and Sweden, all of which had an individual Nature Index Share of more than 100 in 2023.
Source: Nature Index. Data analysis by Aayush Kagathra. Data visualization by Simon Baker and Tanner Maxwell.
Genome sequences of West Nile virus (pictured) are being uploaded and shared on a new online database. Credit: Dr Linda Stannard, UCT/Science Photo Library
A new database for researchers to share the genomes of dangerous viruses promises to solve many of the problems that hamper existing alternatives. But first, researchers must be convinced to use it.
Pathoplexus — a portmanteau of pathogen and plexus — was launched last month, and the team of scientists behind the database hopes that it will encourage more researchers to share genetic sequences of known and emerging viruses of public-health importance.
Sharing sequences as quickly as possible is important for identifying new viruses and tracking changes that could make them more dangerous to humans, as well as for designing vaccines, says Edward Holmes, a virologist at the University of Sydney in Australia.
Pathoplexus currently focuses on four viruses that are not specifically included in other databases: Crimean–Congo Hemorrhagic Fever Virus, Ebola Sudan, Ebola Zaire and West Nile Virus. Other pathogens will be added later, the team says.
Existing hurdles
Among the largest existing repositories is GenBank in the United States, which offers unrestricted access to its genomic data. But public access means that anyone can theoretically use the data to publish scientific papers, without acknowledging the data owners. This has discouraged scientists, particularly those from lower-income countries, from sharing their data quickly, such as during a public-health emergency. An alternative repository, GISAID, requires users to register, agree to acknowledge the data owners and make their best efforts to collaborate with the owners. The database was designed to ensure the rights of data submitters.
GISAID was hugely popular during the COVID-19 pandemic, and it contains close to 17 million sequences of SARS-CoV-2, the virus behind COVID-19. But researchers have raised concerns around transparency in its governance, how it mediates disputes over credit and how it sanctions those it believes to have violated its conditions for use.
“GISAID has led to a lot of frustration in the past few years,” but the scientific community have also learnt lessons on how to do things better, says Spyros Lytras, an evolutionary virologist at the University of Tokyo. “Starting from scratch is what we need as a community, and Pathoplexus might be the solution.”
A representative for GISAID said, in an email, that the trust it has with the scientific community is strong, and that more than 70,000 researchers use the site. The roles of its governing bodies and funding sources are displayed on its website, and their terms of use haven’t changed since it was founded in 2008, the representative said.
Building trust
Pathoplexus offers some protections for users. For instance, researchers can set restrictions on how their data are used, such as not allowing them to be included as a key focus of scientific publications for up to a year without their explicit permission. This should give data owners enough time to submit a manuscript on their findings.
Users must also credit the data owners in their publications. “We aim to build a community where researchers feel confident that their contributions will be respected and properly credited,” says Jamie Southgate, a member of Pathoplexus and the head of operations at the global coalition Public Health Alliance for Genomic Epidemiology, based in Cape Town, South Africa.
Pathoplexus doesn’t block individuals who breach the terms of use from accessing the site, which GISAID has done in rare cases. Instead, if published data breach the terms, the team will approach the journals to ensure that the data are used in accordance with the way in which they were shared, says Emma Hodcroft, a co-founder of Pathoplexus and a molecular epidemiologist at the Swiss Tropical and Public Health Institute in Basel, Switzerland. “We have tried to be incredibly explicit” about the terms, she says.
“It’s a good, clever solution,” says Senjuti Saha, a molecular microbiologist at the Child Health Research Foundation in Dhaka, who agrees with the approach of reaching out to publishers. “That’s the way it should be.” She thinks that Pathoplexus’s transparency will breed trust among the scientific community.
But it’s too early to say whether the repository will solve the current data-sharing problems, says Saha. “It is an excellent and fantastic first step.”
Users might also stick to sharing sequences on local databases. For instance, in China, researchers are probably more likely to publish sequences for emerging viruses on Chinese databases, says Shi Mang, an evolutionary biologist at Sun Yat-sen University in Shenzhen, China, who is also on Pathoplexus’s scientific advisory board. But for established viruses, they are likely to use repositories with well-maintained collections, which Pathoplexus offers.
Improved experience
Pathoplexus’s creators have tried to improve the user experience, such as making uploading as easy as possible. Pathoplexus also checks for errors in the sequence data and accompanying information and assists with organizing viruses into subtypes. “This is actually what attracted me to this database,” says Shi. Incorrect sequences in current repositories can cause lots of trouble for researchers, he says.
So far, Pathoplexus has used GenBank data for the four viruses to populate the site. Thousands of people have visited the site, and 50 have created accounts to submit data, but none have submitted sequences, says Hodcroft. “We did not expect high volumes of data for the pathogens that we’ve launched with.”
Researchers who work on other viruses will have to wait until the database expands to include them. And to expand, the team needs to secure long-term funding. The site is currently being run by volunteers and donated computing time, which ends in about six months. Hodcroft says her priority right now is to appeal to donors. “I’m cautiously hopeful.”
The ‘file-drawer problem’, where findings with null or negative results gather dust and are left unpublished, is well known in science. There has been an overriding perception that studies with positive or significant findings are more important, but this bias can have real-world implications, skewing perceptions of drug efficacies, for example.
Multiple efforts to get negative results published have been put forward or attempted, with some researchers saying that the incentive structures in academia, and the ‘publish or perish’ culture, need to be overturned in order to end this bias.
This is an audio version of our Feature: So you got a null result. Will anyone publish it?
Studies that try to replicate the findings of published research are hard to come by: it can be difficult to find funders to support them and journals to publish them. And when these papers do get published, it’s not easy to locate them, because they are rarely linked to the original studies.
A database described in a preprint posted in April1 aims to address these issues by hosting replication studies from the social sciences and making them more traceable and discoverable. It was launched as part of the Framework for Open and Reproducible Research Training (FORTT), a community-driven initiative that teaches principles of open science and reproducibility to researchers.
The initiative follows other efforts to improve the accessibility of replication work in science, such as the Institute for Replication, which hosts a database listing studies published in selected economics and politics journals that academics can choose to replicate.
The team behind the FORTT database hopes that it will draw more attention to replication studies, which it argues is a fundamental part of science. The database can be accessed through the web application Shiny, and will soon be available on the FORTT website.
Nature Index spoke to one of the project’s leaders, Lukas Röseler, a metascience researcher and director of the University of Münster’s Center for Open Science in Germany.
Why did you create this database?
We’re trying to make it easier for researchers to make their replication attempts public, because it’s often difficult to publish them, regardless of their outcome.
We also wanted to make it easier to track replication studies. If you’re building on previous research and want to check whether replication studies have already been done, it’s often difficult to find them, partly because journals tend to not link them to the original work.
We started out with psychology, which has been hit hard by the replication crisis, and have branched out to studies in judgement and decision-making, marketing and medicine. We are now looking into other fields to understand how their researchers conduct replication studies and what replication means in those contexts.
Who might want to use the database?
A mentor of mine wrote a textbook on social psychology and said that he had no easy way of screening his 50 pages of references for replication attempts. Now, he can enter his references into our database and check which studies have been replicated.
The database can also be used to determine the effectiveness of certain procedures by tracking the replication history of studies. Nowadays, for instance, academics are expected to pre-register their studies — publishing their research design, hypotheses and analysis plans before conducting the study — and make their data freely available online. We would like to empirically see whether interventions such as these affect how likely a study is to be replicable.
2024 Research Leaders
How is the database updated?
It is currently an online spreadsheet, which we created by manually adding the original findings, their replication studies and their outcomes. So far, we have more than 3,300 entries — or replication findings — of just under 1,100 original studies. There are often multiple findings in one study; a replication study might include attempts to replicate four different findings, constituting four entries.
There are hundreds of volunteers who are collecting replications and logging studies on the spreadsheet. You can either just enter a study so that it’s findable, or include both the original study and the replication findings.
We are in contact with teams that conduct a lot of replication research, and we regularly issue calls for people to add their studies. This is a crowdsourced effort and a large proportion of it is based on the FORTT replications and reverses project, which is also crowdsourced. It aims to collate replications and ‘reversal effects’ in social science, in which replication attempts have results in the opposite direction compared with the original.
Do you plan to automate this process?
We are absolutely looking into ways to automate this. For instance, we are working on a machine-readable manuscript template, in which people can enter their manuscript and have it automatically read into the database.
We have code that automatically recognizes DOIs and cross checks them with all the original studies in the database to check whether there is a match. We are working on turning this into a search engine, but it’s beyond our capabilities and resources at the moment.
Does your database provide any data on the replications it hosts?
If you go to our website, there is a replication tracker, where you can see the percentage of studies that were able to replicate original findings, and those that failed to do so.
In a version of the database that we will launch in the coming months, users will be able to choose the criteria by which they judge whether a study successfully replicated the original findings. Right now, it’s all based on how strong the effect sizes — a measure of the relationship between two variables — were on both the original study and the replication attempts, but there are many other criteria and metrics of replication success that we are considering.
We’re also planning to launch a peer-reviewed, open-access journal at FORTT to publish replication studies from various disciplines.
This interview has been edited for length and clarity.
Nature Index’s news and supplement content is editorially independent of its publisher, Springer Nature. For more information about Nature Index, see the homepage.
The definition of copyright in an age of artificial-intelligence tools is an open question, both legally and morally.Credit: Getty
No one knows for sure exactly what ChatGPT — the most famous product of artificial intelligence — and similar tools were trained on. But millions of academic papers scraped from the web are among the reams of data that have been fed into large language models (LLMs) that generate text, and similar algorithms that make images (see Nature632, 715–716; 2024). Should the creators of such training data get credit — and if so, how? There is an urgent need for more clarity around the boundaries of acceptable use.
Few LLMs — even those described as ‘open’ — have developers who are upfront about exactly which data were used for training. But information-rich, long-form text, a category that includes many scientific papers, is particularly valuable. According to an investigation by The Washington Post and the Allen Institute for Artificial Intelligence in Seattle, Washington, material from the open-access journal families PLOS and Frontiers features prominently in a data set called C4, which has been used to train LLMs such as Llama, made by the technology giant Meta. It is also widely suspected that, just as copyrighted books have been used to train LLMs, so have non-open-access research papers.
Science and the new age of AI: a Nature special
One fundamental question concerns what is allowed under current laws. The World Intellectual Property Organization (WIPO), based in Geneva, Switzerland, says that it is unclear whether collecting data or using them to create LLM outputs is considered copyright infringement, or whether these activities fall under one of several exemptions, which differ by jurisdiction. Some publishers are seeking clarity in the courts: in an ongoing case, The New York Times has alleged that the tech firms Microsoft and OpenAI — the company that developed ChatGPT — copied its articles to train their LLMs. To avoid the risk of litigation, more AI firms are now, as recommended by WIPO, purchasing licences from copyright holders for training data. Content owners are also using code on their websites that tells tools scraping data for LLMs whether they are allowed to do so.
Things get much fuzzier when material is published under licences that encourage free distribution and reuse, but that can still have certain restrictions. Creative Commons, a non-profit organization in Mountain View, California, that aims to increase sharing of creative works, says that copying material to train an AI should not generally be treated as infringement. But it also acknowledges concerns about the impact of AI on creators, and how to ensure that AI that is trained on ‘the commons’ — the body of freely available material — contributes to the commons in return.
These broader questions of fairness are particularly pressing for artists, writers and coders, whose livelihoods depend on their creative outputs and whose work risks being replaced by the products of generative AI. But they are also highly relevant for researchers. The move towards open-access publishing explicitly favours the free distribution and reuse of scientific work — and this presumably applies to LLMs, too. Learning from scientific papers can make LLMs better, and some researchers might rejoice if improved AI models could help them to gain new insights.
Credit where it is due
But others are worried about principles such as attribution, the currency by which science operates. Fair attribution is a condition of reuse under CC BY, a commonly used open-access copyright license. In jurisdictions such as the European Union and Japan, there are exemptions to copyright rules that cover factors such as attribution — for text and data mining in research using automated analysis of sources to find patterns, for example. Some scientists see LLM data-scraping for proprietary LLMs as going well beyond what these exemptions were intended to achieve.
Has your paper been used to train an AI model? Almost certainly
In any case, attribution is impossible when a large commercial LLM uses millions of sources to generate a given output. But when developers create AI tools for use in science, a method known as retrieval-augmented generation could help. This technique doesn’t apportion credit to the data that trained the LLM, but does allow the model to cite papers that are relevant to its output, says Lucy Lu Wang, an AI researcher at the University of Washington in Seattle.
Giving researchers the ability to opt out of having their work used in LLM training could also ease their worries. Creators have this right under EU law, but it is tough to enforce in practice, says Yaniv Benhamou, who studies digital law and copyright at the University of Geneva. Firms are devising innovative ways to make it easier. Spawning, a start-up company in Minneapolis, Minnesota, has developed tools to allow creators to opt out of data scraping. Some developers are also getting on board: OpenAI’s Media Manager tool, for example, allows creators to specify how their works can be used by machine-learning algorithms.
Greater transparency can also play a part. The EU’s AI Act, which came into force on 1 August, requires developers to publish a summary of the works used to train their AI models. This could bolster creators’ ability to opt out, and might serve as a template for other jurisdictions. But it remains to be seen how this will work in practice.
Meanwhile, research should continue into whether there is a need for more-radical solutions, such as new kinds of licence or changes to copyright law. Generative AI tools are using a data ecosystem built by open-source movements, yet often ignore the accompanying expectations of reciprocity and reasonable use, says Sylvie Delacroix, a digital-law scholar at King’s College London. The tools also risk polluting the Internet with AI-generated content of dubious quality. By failing to redirect users to the human-made sources on which they were built, LLMs could disincentivize original creation. Without putting more power into the hands of creators, the system will come under severe strain. Regulators and companies must act.
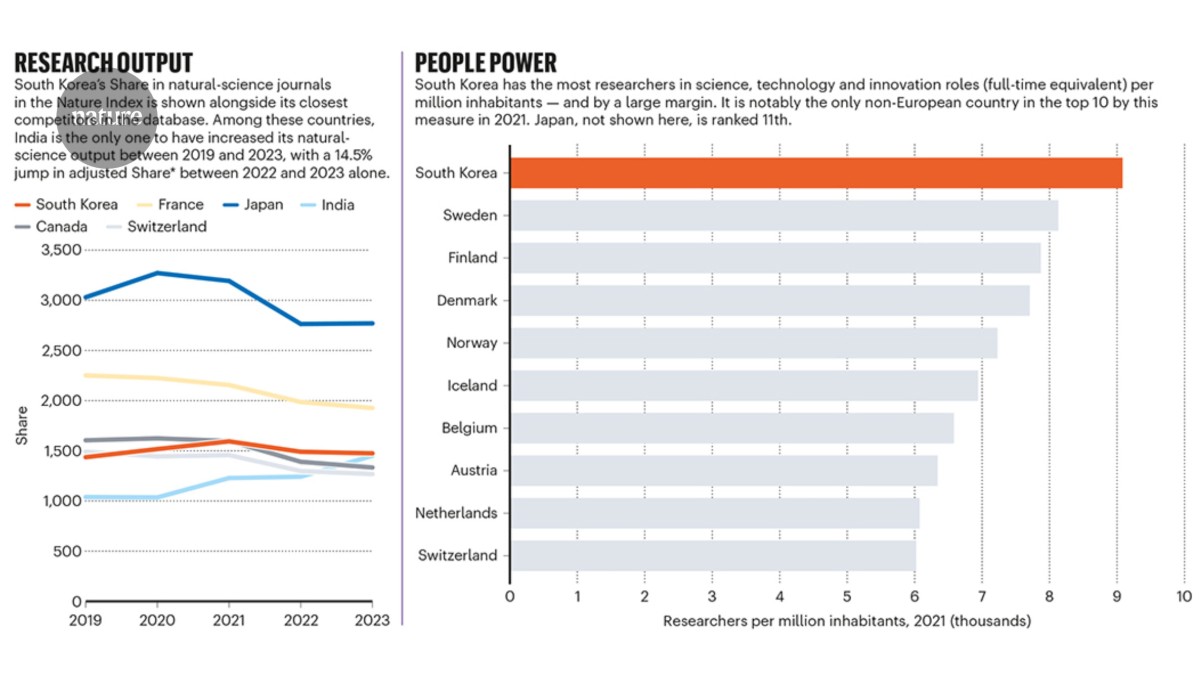
South Korea’s Share in natural-science journals in the Nature Index is shown alongside its closest competitors in the database. Among these countries, India is the only one to have increased its natural-science output between 2019 and 2023, with a 14.5% jump in adjusted Share between 2022 and 2023 alone.
People power
South Korea has the most researchers in science, technology and innovation roles (full-time equivalent) per million inhabitants — and by a large margin. It is notably the only non-European country in the top 10 by this measure in 2021. Japan, not shown here, is ranked 11th.
Subject strengths
A breakdown of subject contributions to countries’ overall 2023 output in journals tracked by the Nature Index is shown for South Korea and some of its closest competitors. With almost 55% of its output attributed to the physical sciences, South Korea joins India in this group as having a dominant subject that is worth more than half of its total output. France and Switzerland, by comparison, have a more balanced output.
On the up
The fastest rising South Korean institutions for the period 2019 to 2023 have recorded very modest gains in natural-science output in the Index, which could speak to the country’s relatively stable performance in recent years. Samsung Group, the only corporate institution in this list, had the largest percentage increase over the period, at 57.98%. This was from a much smaller adjusted Share of 10.77 in 2019, however, compared with Seoul National University at 174.97.
Most improved
The fastest-rising institutions in four natural-science subjects, and in the natural sciences overall, are shown for the period 2019 to 2023. Institutions are ranked according to change in adjusted Share, which for the Pohang University of Science and Technology was larger in the physical sciences than it was in the natural sciences overall.
Source: Nature Index
Big spender
Although South Korea spends more on its research and development as a proportion of its gross domestic product than most other countries in the world, this does not translate to higher Share in the Nature Index. Its output does seem relatively stable, however; among the selected countries shown below, many recorded a decline in Share (per million people) in natural-science journals over the past five years, but South Korea’s drop was smaller than most.
A scanning microscope at Center for Quantum Nanoscience in Ewha Womans University, Seoul.Credit: Caroline Hommel, QNS
With more researchers per capita and a higher spend on research and development than any leading country in the Nature Index, it’s clear that South Korea invests heavily in science. But its ‘bang for buck’ — judged by pitting research spend against output in the Nature Index, measured by Share — is surprisingly low.
Nature Index 2024 South Korea
This disconnect chimes with the many challenges that South Korea faces, including concerns over the country’s status as an innovation powerhouse and signs that its historically close ties between industry and academia might be faltering. Add to the mix the world’s lowest birth rate and declining student numbers, and South Korea seems to be at an inflection point, where it either pivots and adapts, or struggles to keep pace.
Many researchers would like to see the country engage in more diverse partnerships, in addition to those with the United States and China, its two strongest collaborators in the Nature Index. South Korea’s acceptance into the European Union’s Horizon Europe funding programme is a positive step, but domestic conditions need to improve to help it forge more international links. Foreign researchers cite language barriers and cultural divides as hindrances to staying long-term in South Korea, which is affecting recruitment at universities and companies.
What is arguably South Korea’s starkest weakness, meanwhile, could provide an opportunity for renewing its innovation potential: just 23% of its research workforce is female. Addressing the drop-off that occurs during women’s careers might be one way to cement the country’s place as a global leader in science.