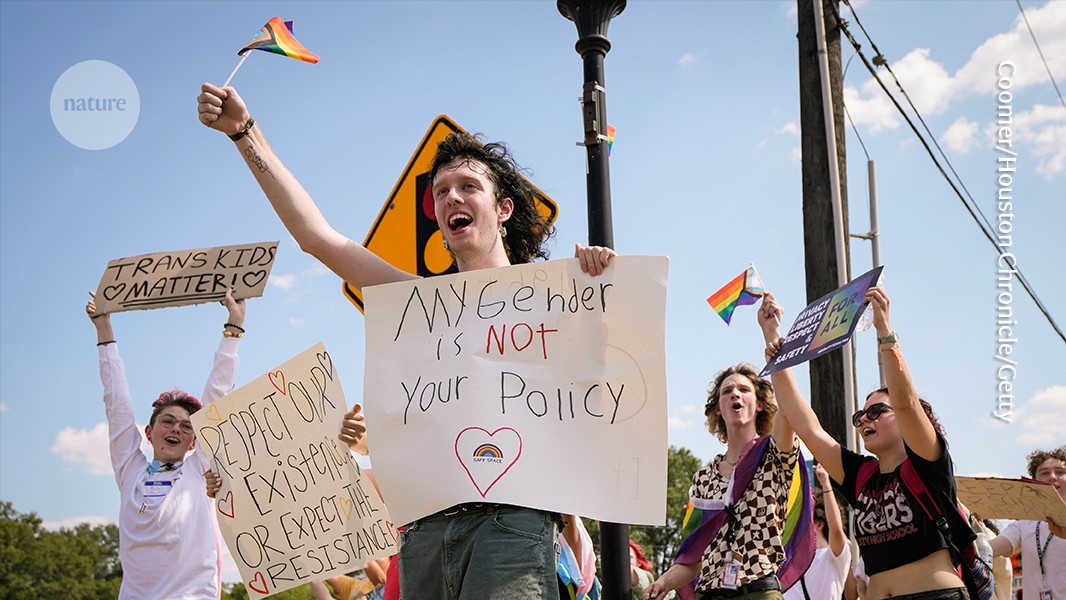In 2023, students protested against a new policy in Texas, where parents would be notified if their child asks to be identified as transgender.Credit: Brett Coomer/Houston Chronicle/Getty
This week, Nature is launching a collection of opinion articles on sex and gender in research. Further articles will be published in the coming months. The series will highlight the necessity and challenges of studying a topic that is both hugely under-researched and, increasingly, the focus of arguments worldwide — many of which are neither healthy nor constructive.
Some scientists have been warned off studying sex differences by colleagues. Others, who are already working on sex or gender-related topics, are hesitant to publish their views. Such a climate of fear and reticence serves no one. To find a way forward we need more knowledge, not less.
We need more-nuanced approaches to exploring sex and gender in research
Nearly 20 researchers from diverse fields, including neuroscience, psychology, immunology and cancer, have contributed to the series, which provides a snapshot of where scholars studying sex and gender are aligned — and where they are not. In time, we hope this collection will help to shape research, and provide a reference point for moderating often-intemperate debates.
In practice, people use sex and gender to mean different things. But researchers studying animals typically use sex to refer to male and female individuals, as defined by various anatomical and other biological features. In studies involving humans, participants are generally asked to identify their own sex and/or gender category. Here, gender usually encompasses social and environmental factors, including gender roles, expectations and identity.
For as long as scientific inquiry has existed, people have mainly studied men or male animals. Even as recently as 2009, only 26% of studies using animals included both female and male individuals, according to a review of 10 fields in the biological sciences1. This bias has had serious consequences. Between 1997 and 2000, for instance, eight prescription drugs were removed from the US market, because clinical testing had not revealed women’s greater risk of developing health problems after taking the drugs.
The tide, however, is turning. Many journals, including those in the Nature Portfolio, and funders, such as the US National Institutes of Health, have developed guidelines and mandates to encourage scientists to consider sex and, where appropriate, gender in their work.
Male–female comparisons are powerful in biomedical research — don’t abandon them
These efforts are reaping benefits2. Studies, for example, are showing that a person’s sex and/or gender can influence their risk of disease and chances of survival when it comes to many common causes of death — including cardiovascular conditions and cancer.
Despite this, many researchers remain unconvinced that the inclusion of sex and gender information is important in their field. Others, who are already doing so, have told Nature that they’re afraid of how their work is perceived and of how it could be misunderstood, or misused.
Because researchers who are exploring the effects of sex and gender come from many disciplines, there will be disagreements. An often-raised and valid concern, for example, is that when researchers compare responses between female and male animals, or between men and women, they exclude those whose sex and/or gender doesn’t fall into a binary categorization scheme. Another is that variability between individuals of the same sex could be more important than that between sexes.
Sometimes sense does seem to get lost in the debates. That the term sex refers to a lot of interacting factors, which are not fully understood, does not invalidate its usefulness as a concept3. That some people misinterpret and misuse findings concerning differences between sexes, particularly in relation to the human brain, should not mean denying that any differences exist.
Tempering the debate
Many of the questions being raised, however, are important to ask, especially given concerns about how best to investigate biological differences between groups of humans, and the continued — and, in some regions, worsening — marginalization of people whose sex and/or gender identity doesn’t fall into narrowly defined norms. Often, such questions and concerns can be addressed through research. For example, studies might find that variability between individuals of the same sex in diet, or body weight, say, are more important predictors of how likely they are to develop anaemia than whether they are male or female.
The fraught quest to account for sex in biology research
The problem, then is not the discussions alone: science exists to examine and interrogate disagreements. Rather, the problem is that debates — and work on sex and gender, in general — are being used to polarize opinions about gender identity. As Arthur Arnold, a biologist at the University of California, Los Angeles, and his colleagues describe in their Comment article, last September, legislation banning gender-affirming medical care for people under 18 years old was introduced in Texas on the basis of claims that everyone belongs to one of two gender groups, and that this reality is settled by science. It isn’t. Scientists are reluctant to study sex and gender, not just because of concerns about the complexity and costs of the research, but also because of current tensions.
But it is crucial that scholars do not refrain from considering the effects of sex and gender if such analyses are relevant to their field. Improved knowledge will help to resolve concerns and allow a scholarly consensus to be reached, where possible. Where disagreements persist, our hope is that Nature’s collection of opinion articles will equip researchers with the tools needed to help them persuade others that going back to assuming that male individuals represent everyone is no longer an option.
Inspired by the nutrition-facts labels that have been displayed on US food packaging since the 1990s, John Willinsky wants to see academic publishing take a similar approach to help to inform readers on how strictly a paper meets scholarly standards.
A team at the Public Knowledge Project, a non-profit organization run by Willinsky and his colleagues at Simon Fraser University in Burnaby, Canada, has been investigating how such a label might be standardized in academic publishing1.
Willinsky spoke to Nature Index about what he hopes to achieve with the initiative.
Why should academic papers have publication-facts labels?
I, like many others, have grown concerned about research integrity. Through transparency, we want to show how closely journals and authors are adhering to the scholarly standards of publishing. We want to help readers, including researchers, the media and the public, to decide whether an article is worth reporting on or citing.
The facts that we have selected for the label include publisher and funder names, the journal’s acceptance rate and the number of peer reviewers. The label also shows whether the paper includes a competing-interests statement and an editor list, where the journal is indexed and whether the data have been made publicly available. Averages for other participating journals are listed, for comparison.
It’s important that such information is readily available. When we conducted an exercise with secondary-school students, asking them to find these facts for a single academic article online, many of them took 30 minutes to do so. Some couldn’t find the information. This finding justifies the need for the label: it shouldn’t take half an hour to establish that a journal adheres to scholarly standards.
How did you create the label?
The US nutrition-facts label has been proved to change people’s behaviour, specifically their food-purchasing habits2. Given that so much work went into the label’s development, I thought it would be wise to build on its design.
On the basis of our early consultations with researchers, editors, science journalists, primary-school teachers and others, we created a prototype with eight elements that reflect scholarly publishing standards. We’re now gathering feedback, and might decide to change some of the facts, or to add others. Some people, for example, suggested that we include the number of days that the peer-review process took to complete.
Is AI ready to mass-produce lay summaries of research articles?
We’ve built in ways to automatically generate the label, to ensure that the format is standardized across journals and articles and to make the label available in several languages. We have created a third-party verification system, too, to ensure that authors’ identities are not revealed to peer reviewers and vice versa. This relies on authors, reviewers and editors using ORCID, the service that provides unique indicators with which to identify researchers.
The label will be displayed on the article landing page of the journal website and will be included in the article PDF.
How are you trialling the label’s use?
We’ve completed work with ten focus groups involving journal editors and authors in the United States and Latin America. We also interviewed 15 science journalists about what kinds of fact they’d want to see at a glance.
We built the label specifically for journals using the scholarly publishing workflow system Open Journal System (OJS), run by the Public Knowledge Project. By the middle of the year, we hope to launch a pilot programme involving more than 100 journals using the OJS. The goal is to explore the prospects of industry-wide implementation of the label by next year.
How could journals be compelled to display such a label?
Unlike the nutrition-facts label, which was mandated by the US government, the publication-facts label is the result of voluntary concern about research integrity in the publishing industry.
Although many groups, such as the International Association of Scientific, Technical and Medical Publishers and the Committee on Publication Ethics, manage concerns about research integrity by releasing guidelines on best practices and accumulating tools to flag suspicious activity, we feel that they have not addressed the fact that open access is public access. We need to adapt our practices to cater to the needs of different audiences, not just those in academia.
Although we’re initially building the label for OJS journals, it is an open-source plug-in that other publishing platforms will easily be able to adapt. The software is currently listed as being ‘under development’ on GitHub and will be shared there on release.
We want to show the publishing industry that we’ve piloted this in our own environment and that it is readily adaptable. We want to show that, although you could build your own label, for the sake of comprehensibility, it’s better to have a common format.
This interview has been edited for length and clarity.
For decades, computing power followed Moore’s law, advancing at a predictable pace. The number of components on an integrated circuit doubled roughly every two years. In 2012, researchers coined the term Eroom’s law (Moore spelled backwards) to describe the contrasting path of drug development1. Over the previous 60 years, the number of drugs approved in the United States per billion dollars in R&D spending had halved every nine years. It can now take more than a billion dollars in funding and a decade of work to bring one new medication to market. Half of that time and money is spent on clinical trials, which are growing larger and more complex. And only one in seven drugs that enters phase I trials is eventually approved.
Nature Index 2024 Health sciences
Some researchers are hoping that the fruits of Moore’s law can help to curtail Eroom’s law. Artificial intelligence (AI) has already been used to make strong inroads into the early stages of drug discovery, assisting in the search for suitable disease targets and new molecule designs. Now scientists are starting to use AI to manage clinical trials, including the tasks of writing protocols, recruiting patients and analysing data.
Reforming clinical research is “a big topic of interest in the industry”, says Lisa Moneymaker, the chief technology officer and chief product officer at Saama, a software company in Campbell, California, that uses AI to help organizations automate parts of clinical trials. “In terms of applications,” she says, “it’s like a kid in a candy store.”
Trial by design
The first step of the clinical-trials process is trial design. What dosages of drugs should be given? To how many patients? What data should be collected on them? The lab of Jimeng Sun, a computer scientist at the University of Illinois Urbana-Champaign, developed an algorithm called HINT (hierarchical interaction network) that can predict whether a trial will succeed, based on the drug molecule, target disease and patient eligibility criteria. They followed up with a system called SPOT (sequential predictive modelling of clinical trial outcome) that additionally takes into account when the trials in its training data took place and weighs more recent trials more heavily. Based on the predicted outcome, pharmaceutical companies might decide to alter a trial design, or try a different drug completely.
A company called Intelligent Medical Objects in Rosemont, Illinois, has developed SEETrials, a method for prompting OpenAI’s large language model GPT-4 to extract safety and efficacy information from the abstracts of clinical trials. This enables trial designers to quickly see how other researchers have designed trials and what the outcomes have been. The lab of Michael Snyder, a geneticist at Stanford University in California, developed a tool last year called CliniDigest that simultaneously summarizes dozens of records from ClinicalTrials.gov, the main US registry for medical trials, adding references to the unified summary. They’ve used it to summarize how clinical researchers are using wearables such as smartwatches, sleep trackers and glucose monitors to gather patient data. “I’ve had conversations with plenty of practitioners who see wearables’ potential in trials, but do not know how to use them for highest impact,” says Alexander Rosenberg Johansen, a computer-science student in Snyder’s lab. “Best practice does not exist yet, as the field is moving so fast.”
Most eligible
The most time-consuming part of a clinical trial is recruiting patients, taking up to one-third of the study length. One in five trials don’t even recruit the required number of people, and nearly all trials exceed the expected recruitment timelines. Some researchers would like to accelerate the process by relaxing some of the eligibility criteria while maintaining safety. A group at Stanford led by James Zou, a biomedical data scientist, developed a system called Trial Pathfinder that analyses a set of completed clinical trials and assesses how adjusting the criteria for participation — such as thresholds for blood pressure and lymphocyte counts — affects hazard ratios, or rates of negative incidents such as serious illness or death among patients. In one study2, they applied it to drug trials for a type of lung cancer. They found that adjusting the criteria as suggested by Trial Pathfinder would have doubled the number of eligible patients without increasing the hazard ratio. The study showed that the system also worked for other types of cancer and actually reduced harmful outcomes because it made sicker people — who had more to gain from the drugs — eligible for treatment.
Sources: IQVIA Pipeline Intelligence (Dec. 2022)/IQVIA Institute (Jan. 2023)
AI can eliminate some of the guesswork and manual labour from optimizing eligibility criteria. Zou says that sometimes even teams working at the same company and studying the same disease can come up with different criteria for a trial. But now several firms, including Roche, Genentech and AstraZeneca, are using Trial Pathfinder. More recent work from Sun’s lab in Illinois has produced AutoTrial, a method for training a large language model so that a user can provide a trial description and ask it to generate an appropriate criterion range for, say, body mass index.
Once researchers have settled on eligibility criteria, they must find eligible patients. The lab of Chunhua Weng, a biomedical informatician at Columbia University in New York City (who has also worked on optimizing eligibility criteria), has developed Criteria2Query. Through a web-based interface, users can type inclusion and exclusion criteria in natural language, or enter a trial’s identification number, and the program turns the eligibility criteria into a formal database query to find matching candidates in patient databases.
Weng has also developed methods to help patients look for trials. One system, called DQueST, has two parts. The first uses Criteria2Query to extract criteria from trial descriptions. The second part generates relevant questions for patients to help narrow down their search. Another system, TrialGPT, from Sun’s lab in collaboration with the US National Institutes of Health, is a method for prompting a large language model to find appropriate trials for a patient. Given a description of a patient and clinical trial, it first decides whether the patient fits each criterion in a trial and offers an explanation. It then aggregates these assessments into a trial-level score. It does this for many trials and ranks them for the patient.
Helping researchers and patients find each other doesn’t just speed up clinical research. It also makes it more robust. Often trials unnecessarily exclude populations such as children, the elderly or people who are pregnant, but AI can find ways to include them. People with terminal cancer and those with rare diseases have an especially hard time finding trials to join. “These patients sometimes do more work than clinicians in diligently searching for trial opportunities,” Weng says. AI can help match them with relevant projects.
AI can also reduce the number of patients needed for a trial. A start-up called Unlearn in San Francisco, California, creates digital twins of patients in clinical trials. Based on an experimental patient’s data at the start of a trial, researchers can use the twin to predict how the same patient would have progressed in the control group and compare outcomes. This method typically reduces the number of control patients needed by between 20% and 50%, says Charles Fisher, Unlearn’s founder and chief executive. The company works with a number of small and large pharmaceutical companies. Fisher says digital twins benefit not only researchers, but also patients who enrol in trials, because they have a lower chance of receiving the placebo.
Source: Citeline Trialtrove/IQVIA Institute (Jan. 2023)
Patient maintenance
The hurdles in clinical trials don’t end once patients enrol. Drop-out rates are high. In one analysis of 95 clinical trials, nearly 40% of patients stopped taking the prescribed medication in the first year. In a recent review article3, researchers at Novartis mentioned ways that AI can help. These include using past data to predict who is most likely to drop out so that clinicians can intervene, or using AI to analyse videos of patients taking their medication to ensure that doses are not missed.
Chatbots can answer patients’ questions, whether during a study or in normal clinical practice. One study4 took questions and answers from Reddit’s AskDocs forum and gave the questions to ChatGPT. Health-care professionals preferred ChatGPT’s answers to the doctors’ answers nearly 80% of the time. In another study5, researchers created a tool called ChatDoctor by fine-tuning a large language model (Meta’s LLaMA-7B) on patient-doctor dialogues and giving it real-time access to online sources. ChatDoctor could answer questions about medical information that was more recent than ChatGPT’s training data.
Putting it together
AI can help researchers manage incoming clinical-trial data. The Novartis researchers reported that it can extract data from unstructured reports, as well as annotate images or lab results, add missing data points (by predicting values in results) and identify subgroups among a population that responds uniquely to a treatment. Zou’s group at Stanford has developed PLIP, an AI-powered search engine that lets users find relevant text or images within large medical documents. Zou says they’ve been talking with pharmaceutical companies that want to use it to organize all of the data that comes in from clinical trials, including notes and pathology photos. A patient’s data might exist in different formats, scattered across different databases. Zou says they’ve also done work with insurance companies, developing a language model to extract billing codes from medical records, and that such techniques could also extract important clinical trial data from reports such as recovery outcomes, symptoms, side effects and adverse incidents.
To collect data for a trial, researchers sometimes have to produce more than 50 case report forms. A company in China called Taimei Technology is using AI to generate these automatically based on a trial’s protocol.
A few companies are developing platforms that integrate many of these AI approaches into one system. Xiaoyan Wang, who heads the life-science department at Intelligent Medical Objects, co-developed AutoCriteria, a method for prompting a large language model to extract eligibility requirements from clinical trial descriptions and format them into a table. This informs other AI modules in their software suite, such as those that find ideal trial sites, optimize eligibility criteria and predict trial outcomes. Soon, Wang says, the company will offer ChatTrial, a chatbot that lets researchers ask about trials in the system’s database, or what would happen if a hypothetical trial were adjusted in a certain way.
The company also helps pharmaceutical firms to prepare clinical-trial reports for submission to the US Food and Drug Administration (FDA), the organization that gives final approval for a drug’s use in the United States. What the company calls its Intelligent Systematic Literature Review extracts data from comparison trials. Another tool searches social media for what people are saying about diseases and drugs in order to demonstrate unmet needs in communities, especially those that feel underserved. Researchers can add this information to reports.
Zifeng Wang, a student in Sun’s lab, in Illinois, says he’s raising money with Sun and another co-founder, Benjamin Danek, for a start-up called Keiji AI. A product called TrialMind will offer a chatbot to answer questions about trial design, similar to Xiaoyan Wang’s. It will do things that might normally require a team of data scientists, such as write code to analyse data or produce visualizations. “There are a lot of opportunities” for AI in clinical trials, he says, “especially with the recent rise of larger language models.”
At the start of the pandemic, Saama worked with Pfizer on its COVID-19 vaccine trial. Using Saama’s AI-enabled technology, SDQ, they ‘cleaned’ data from more than 30,000 patients in a short time span. “It was the perfect use case to really push forward what AI could bring to the space,” Moneymaker says. The tool flags anomalous or duplicate data, using several kinds of machine-learning approaches. Whereas experts might need two months to manually discover any issues with a data set, such software can do it in less than two days.
Other tools developed by Saama can predict when trials will hit certain milestones or lower drop-out rates by predicting which patients will need a nudge. Its tools can also combine all the data from a patient — such as lab tests, stats from wearable devices and notes — to assess outcomes. “The complexity of the picture of an individual patient has become so huge that it’s really not possible to analyse by hand anymore,” Moneymaker says.
Xiaoyan Wang notes that there are several ethical and practical challenges to AI’s deployment in clinical trials. AI models can be biased. Their results can be hard to reproduce. They require large amounts of training data, which could violate patient privacy or create security risks. Researchers might become too dependent on AI. Algorithms can be too complex to understand. “This lack of transparency can be problematic in clinical trials, where understanding how decisions are made is crucial for trust and validation,” she says. A recent review article6 in the International Journal of Surgery states that using AI systems in clinical trials “can’t take into account human faculties like common sense, intuition and medical training”.
Moneymaker says the processes for designing and running clinical trials have often been slow to change, but adds that the FDA has relaxed some of its regulations in the past few years, leading to “a spike of innovation”: decentralized trials and remote monitoring have increased as a result of the pandemic, opening the door for new types of data. That has coincided with an explosion of generative-AI capabilities. “I think we have not even scratched the surface of where generative-AI applicability is going to take us,” she says. “There are problems we couldn’t solve three months ago that we can solve now.”
Last year, the Nature Index was broadened to include author affiliations from articles in more than 60 medical journals. The expansion, which covers all major disciplines and specialities in clinical medicine and surgery, offers new insights into global publishing trends in the health sciences. This is the first supplement to explore some of those trends.
Nature Index 2024 Health sciences
Two things immediately stand out. The first is that the United States dominates high-quality output in the health sciences, contributing a Share of 8,468 to publications in the Nature Index. China, which in 2023 overtook the United States in natural-sciences output in the database, trails in a distant second place, with a Share of 2,108.
The second noticeable data point is the dominance of Harvard University in the field. The institution, based in Cambridge, Massachusetts, has a Share (822) that is almost three times higher than the second-ranked institution, the US National Institutes of Health (290).
An extraordinary amount of money is invested in health-sciences research, but this hasn’t translated to a faster pipeline for new therapies. The increasing complexity of clinical trials is part of the problem, and something that researchers are hoping artificial intelligence can help to address. Others are rethinking how therapies are assessed in trials to make the results more meaningful. For example, could data impact people with Alzheimer’s and other progressive conditions by measuring how many ‘good years’ a medication can give, rather than comparing scores on cognitive tests?
Outside clinical trials, there are structural weaknesses in health-sciences research that need urgent attention, such as the lack of women in leadership positions. If institutions do not work harder to increase diversity at the top levels of academia, they risk damaging the talent pipeline and ultimately health outcomes for everyone.
The All of Us programme aims to recruit one million people from ethnic and socio-economic groups that are typically under-represented in biomedical studies.Credit: Barbara Alper/Getty
A massive US programme that aims to improve health care by focusing on the genomes and health profiles of historically underrepresented groups has begun to yield results.
Analyses of up to 245,000 genomes gathered by the All of Us programme, run by the US National Institutes of Health in Bethesda, Maryland, have uncovered more than 275 million new genetic markers, nearly 150 of which might contribute to type 2 diabetes. The work has also identified gaps in genetics research on non-white populations. The findings were published on 19 February in a package of papers in Nature1,2, Communications Biology3 and Nature Medicine4.
They are a “nice distillation of the All of Us resource — what it is and what it can do”, says Michael Inouye, a computational genomicist at the University of Cambridge, UK. “This is going to be the go-to data set” for genetics researchers who want to know whether their findings are generalizable to a broad population or apply to only a limited one, he adds.
Bridging the gap
Researchers have long acknowledged the lack of diversity in the genomes available for them to study, says Jibril Hirbo, a geneticist at Vanderbilt University Medical Center in Nashville, Tennessee, who studies the genetics of health disparities. One study5 that looked at data gathered up until January 2019 found that 78% of people in most large-scale genomic studies of disease were of European descent. This has exacerbated existing health disparities, particularly for non-white individuals, Hirbo says. When researchers choose genetic or molecular targets for new medicines or create models to predict who is at risk of developing a disease, they tend to make decisions on the basis of non-diverse data because that’s all that has been available.
Facing up to injustice in genome science
The All of Us programme, which has received over US$3.1 billion to date and plans to assemble detailed health profiles for one million people in the United States by the end of 2026, aims to bridge that gap, says Andrea Ramirez, the programme’s chief data officer. It began enrolling people in 2018, and released its first tranche of data — about 100,000 whole genomes — in 2022. By April 2023, it had enrolled 413,000 anonymized participants, 46% of whom belong to a minority racial or ethnic group, and had shared nearly 250,000 genomes. By comparison, the world’s largest whole-genome data set, the UK Biobank, has so far released about half a million genomes, around 88% of which are from white people.
The All of Us data set is “a huge resource, particularly of African American, Hispanic and Latin American genomes, that’s massively missing from the vast majority of large-scale biobank resources and genomics consortia”, says Alicia Martin, a population geneticist at Massachusetts General Hospital in Boston.
In addition to the genomes, the database includes some participants’ survey responses, electronic health records and data from wearable devices, such as Fitbits, that report people’s activity, “making this one of the most powerful resources of genomic data”, Martin says.
An urgent need
A study in Nature on type 2 diabetes2 is an example of the power of using a database that includes diverse genomes, Ramirez says. The condition, which affects about one in ten people in the United States, can be caused by many distinct biological mechanisms involving various genes. The researchers analysed genetic information from several databases, including All of Us, for a total of more than 2.5 million people; nearly 40% of the data came from individuals not of European ancestry. The team found 611 genetic markers that might drive the development and progression of the disease, 145 of which have never been reported before. These findings could be used to develop “genetically informed diabetes care”, the authors write.
World’s biggest set of human genome sequences opens to scientists
In another of the studies3, researchers used All of Us data to examine pathogenic variants — that is, genetic differences that increase a person’s risk of developing a particular disease. They found that, among the genomes of people with European ancestry, 2.3% had a pathogenic variant. Among genomes from people with African ancestry, however, this fell to 1.6%.
Study co-author Eric Venner, a computational geneticist at Baylor College of Medicine in Houston, Texas, cautions that there should be no biological reason for the differences. He says that the disparity is probably the result of more research having been conducted on people of European ancestry; we simply know more about which mutations in this population lead to disease. In fact, the researchers found more variants of unknown risk in the genomes of people with non-European ancestry than in those with European ancestry, he adds. This underscores the urgent need to study non-European genomes in more detail, Venner says.
Updating models
Gathering and using more genomic and health data from diverse populations will be especially important for generating more accurate ‘polygenic risk scores’. These provide a picture of a person’s risk of developing a disease as a result of their genetics.
US tailored-medicine project aims for ethnic balance
To calculate a score for a particular disease, researchers develop an algorithm that is trained on thousands of genomes from people who either do or don’t have the disease. A person’s own score can then be calculated by feeding their genetic data into the algorithm.
Previous research6 has shown that the scores, which might soon be used in the clinic for personalized health care, tend to be less accurate for minority populations than for majority ones. In one of the current papers4, researchers used the more-inclusive All of Us data to improve the landscape: they calibrated and validated scores for 23 conditions and recommended 10 to be prioritized for use in the clinic, for conditions including coronary heart disease and diabetes. Martin applauds these efforts, but she hopes that future studies address how physicians and others in the clinic interpret these scores, and whether the scores can improve a person’s health in the long term because of the treatment decisions they elicit.
The All of Us programme plans to release a tranche of data every year, representing new enrolees and genomes, including one later in 2024, Ramirez says. It’s excellent that diverse data are coming in, Hirbo says, adding that he would like to see existing algorithms that were trained mainly on the genomes of people of European ancestry updated soon. “The models are still way behind,” he says.
Biodiversity science is benefiting from volunteer researchers (seen here working at Chicago’s Fields Museum).Credit: Nancy Stone/Chicago Tribune/Tribune News Service/Getty
The ‘open science’ concept is gaining more followers, not least through the efforts of the cultural organization UNESCO. Over the past several years, the organization has been consulting on how science can become more collaborative, transparent, accessible, equitable and inclusive, which are all attributes of open science. And in 2021, it published a framework for what a genuinely open science could look like.
At the end of last year, UNESCO, which is headquartered in Paris, published a report on the current status of this endeavour. The report makes it clear that, although there are instances of good practice, there is still much work to do to fulfil the potential of open science globally.
In 2021, UNESCO’s member states agreed on a definition of open science that includes open access to scientific knowledge (including the humanities and social sciences); open access to research infrastructure; open collaboration between scientists and ‘societal actors’ (essentially, all those who are not scientists); and open dialogue between different knowledge systems, including between scientific knowledge and Indigenous knowledge.
The world’s goals to save humanity are hugely ambitious — but they are still the best option
Member states also pledged to incorporate the concept into their research systems, including using open-science principles in publicly funded research; supporting non-profit and community-driven publishing; encouraging the publication of research in more languages; and incentivizing the private sector to join discussions about achieving open-science goals.
UNESCO’s report describes several examples of positive initiatives, such as in research collaboration, open-access scientific publishing and public engagement in science. For example, in 2020, the Brazilian government launched the National Platform of Research Infrastructure, a digital platform in which scientific institutions can register their available infrastructure, and make it available to researchers outside their organization. This is an excellent way to spread access to expensive equipment across the research community.
Meanwhile, South African policymakers are consulting researchers to help to create a national open-science policy for the whole country. The aim here is to build more transparency, scrutiny and reproducibility into the country’s research system. The policy will also include measures to monitor progress.
The European Commission, based in Brussels, was an early proponent of open science. Between 2002 and 2020, it increased its funding for ‘societal engagement’ projects from €88 million to €462 million — an amount that is now equivalent to US$500 million. Moreover, a decade ago, all scientific publications arising from the European Union’s €80 billion Horizon 2020 programme needed to be published open-access. Citizen science is another growing area in open science with much promise, UNESCO notes. By 2018, half of all records in the Global Biodiversity Information Facility — an international open-access data repository based in Copenhagen — were from citizen scientists, up from around 10% in around 2007.
Other indicators are less rosy, however. Around three-quarters (73%) of publications in open-access repositories are in just six languages — with nearly half (46%) being in English alone. And in spite of some of the progress mentioned, overall the report finds that scientific institutions, such as universities, national science academies and journals, are struggling to include communities, in all their diversity, in the process of creating scientific knowledge itself.
Open science, done wrong, will compound inequities
Open science aligns with UNESCO’s founding mission for science and education to benefit all of humanity; and with the idea that access to science is a human right. But the organization’s interest in open science goes beyond these broad founding principles.
The UN’s Sustainable Development Goals (SDGs), adopted in 2015, are humanity’s best attempt to map a pathway towards a better future — and a more open approach to science could have a larger part to play in achieving them.
That effort needs as much help as it can get: only about 12% of the SDG targets are likely to be met by the 2030 deadline. Monitoring SDG indicators is one obvious way that citizen scientists can help. Some of the largest gaps in the collection of relevant SDG data are in low- and middle-income countries, which is where citizen research can really make a difference. In 2020, Dilek Fraisl, a data researcher at the International Institute for Applied Systems Analysis in Laxenburg, Austria, and her colleagues found that citizen-science projects were already helping to monitor at least five SDG indicators (D. Fraisl et al. Sustain. Sci. 15, 1735–1751; 2020). At the time, more than half of the data collected on indicators for sustainable cities, good health and well-being, and clean water and sanitation were provided by citizen scientists.
There’s scope for citizen scientists to do more. UN agencies have also recognized the potential of connecting citizen scientists with official data bodies. The UN Statistical Commission and UN Women are working with researchers in civil society organizations to produce resources, such as toolkits for producers of citizen-generated data.
The UNESCO report shines a much-needed light on some promising developments in open science. The challenge will be how to accumulate individual examples of good practice into something similar to a critical mass, so that, in cases such as monitoring the SDGs, they can be harnessed to get the world to where it needs to be.
Hunter Moseley says that good reproducibility practices are essential to fully harness the potential of big data.Credit: Hunter N.B. Moseley
We are in the middle of a data-driven science boom. Huge, complex data sets, often with large numbers of individually measured and annotated ‘features’, are fodder for voracious artificial intelligence (AI) and machine-learning systems, with details of new applications being published almost daily.
But publication in itself is not synonymous with factuality. Just because a paper, method or data set is published does not mean that it is correct and free from mistakes. Without checking for accuracy and validity before using these resources, scientists will surely encounter errors. In fact, they already have.
In the past few months, members of our bioinformatics and systems-biology laboratory have reviewed state-of-the-art machine-learning methods for predicting the metabolic pathways that metabolites belong to, on the basis of the molecules’ chemical structures1. We wanted to find, implement and potentially improve the best methods for identifying how metabolic pathways are perturbed under different conditions: for instance, in diseased versus normal tissues.
We found several papers, published between 2011 and 2022, that demonstrated the application of different machine-learning methods to a gold-standard metabolite data set derived from the Kyoto Encyclopedia of Genes and Genomes (KEGG), which is maintained at Kyoto University in Japan. We expected the algorithms to improve over time, and saw just that: newer methods performed better than older ones did. But were those improvements real?
Data leaks
Scientific reproducibility enables careful vetting of data and results by peer reviewers as well as by other research groups, especially when the data set is used in new applications. Fortunately, in keeping with best practices for computational reproducibility, two of the papers2,3 in our analysis included everything that is needed to put their observations to the test: the data set they used, the computer code they wrote to implement their methods and the results generated from that code. Three of the papers2–4 used the same data set, which allowed us to make direct comparisons. When we did so, we found something unexpected.
It is common practice in machine learning to split a data set in two and to use one subset to train a model and another to evaluate its performance. If there is no overlap between the training and testing subsets, performance in the testing phase will reflect how well the model learns and performs. But in the papers we analysed, we identified a catastrophic ‘data leakage’ problem: the two subsets were cross-contaminated, muddying the ideal separation. More than 1,700 of 6,648 entries from the KEGG COMPOUND database — about one-quarter of the total data set — were represented more than once, corrupting the cross-validation steps.
NatureTech
When we removed the duplicates in the data set and applied the published methods again, the observed performance was less impressive than it had first seemed. There was a substantial drop in the F1 score — a machine-learning evaluation metric that is similar to accuracy but is calculated in terms of precision and recall — from 0.94 to 0.82. A score of 0.94 is reasonably high and indicates that the algorithm is usable in many scientific applications. A score of 0.82, however, suggests that it can be useful, but only for certain applications — and only if handled appropriately.
It is, of course, unfortunate that these studies were published with flawed results stemming from the corrupted data set; our work calls their findings into question. But because the authors of two of the studies followed best practices in computational scientific reproducibility and made their data, code and results fully available, the scientific method worked as intended, and the flawed results were detected and (to the best of our knowledge) are being corrected.
The third team, as far as we can tell, included neither their data set nor their code, making it impossible for us to properly evaluate their results. If all of the groups had neglected to make their data and code available, this data-leakage problem would have been almost impossible to catch. That would be a problem not just for the studies that were already published, but also for every other scientist who might want to use that data set for their own work.
More insidiously, the erroneously high performance reported in these papers could dissuade others from attempting to improve on the published methods, because they would incorrectly find their own algorithms lacking by comparison. Equally troubling, it could also complicate journal publication, because demonstrating improvement is often a requirement for successful review — potentially holding back research for years.
Encouraging reproducibility
So, what should we do with these erroneous studies? Some would argue that they should be retracted. We would caution against such a knee-jerk reaction — at least as a blanket policy. Because two of the three papers in our analysis included the data, code and full results, we could evaluate their findings and flag the problematic data set. On one hand, that behaviour should be encouraged — for instance, by allowing the authors to publish corrections. On the other, retracting studies with both highly flawed results and little or no support for reproducible research would send the message that scientific reproducibility is not optional. Furthermore, demonstrating support for full scientific reproducibility provides a clear litmus test for journals to use when deciding between correction and retraction.
Now, scientific data are growing more complex every day. Data sets used in complex analyses, especially those involving AI, are part of the scientific record. They should be made available — along with the code with which to analyse them — either as supplemental material or through open data repositories, such as Figshare (Figshare has partnered with Springer Nature, which publishes Nature, to facilitate data sharing in published manuscripts) and Zenodo, that can ensure data persistence and provenance. But those steps will help only if researchers also learn to treat published data with some scepticism, if only to avoid repeating others’ mistakes.