
[ad_1]
The Internet is a vast ocean of human knowledge, but it isn’t infinite. And artificial intelligence (AI) researchers have nearly sucked it dry.
The past decade of explosive improvement in AI has been driven in large part by making neural networks bigger and training them on ever-more data. This scaling has proved surprisingly effective at making large language models (LLMs) — such as those that power the chatbot ChatGPT — both more capable of replicating conversational language and of developing emergent properties such as reasoning. But some specialists say that we are now approaching the limits of scaling. That’s in part because of the ballooning energy requirements for computing. But it’s also because LLM developers are running out of the conventional data sets used to train their models.
A prominent study1 made headlines this year by putting a number on this problem: researchers at Epoch AI, a virtual research institute, projected that, by around 2028, the typical size of data set used to train an AI model will reach the same size as the total estimated stock of public online text. In other words, AI is likely to run out of training data in about four years’ time (see ‘Running out of data’). At the same time, data owners — such as newspaper publishers — are starting to crack down on how their content can be used, tightening access even more. That’s causing a crisis in the size of the ‘data commons’, says Shayne Longpre, an AI researcher at the Massachusetts Institute of Technology in Cambridge who leads the Data Provenance Initiative, a grass-roots organization that conducts audits of AI data sets.
The imminent bottleneck in training data could be starting to pinch. “I strongly suspect that’s already happening,” says Longpre.
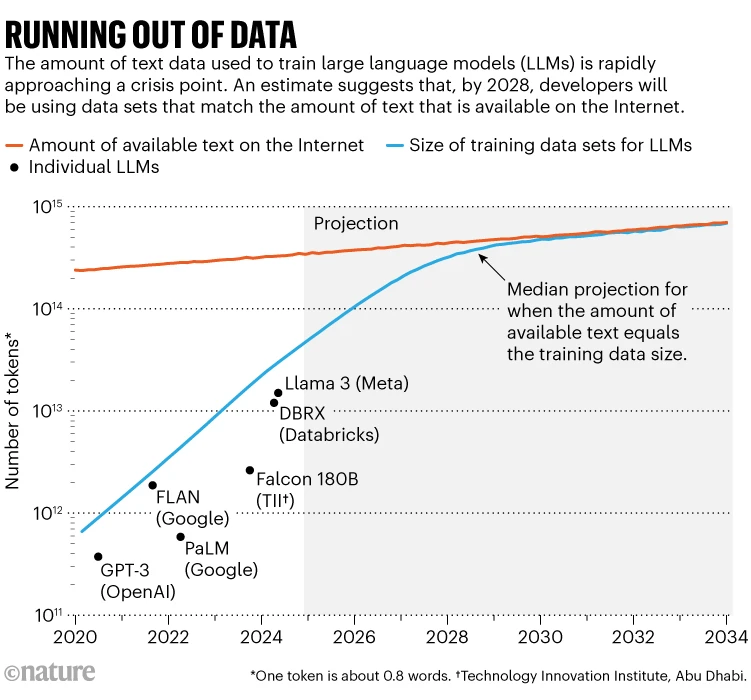
Source: Ref. 1
Although specialists say there’s a chance that these restrictions might slow down the rapid improvement in AI systems, developers are finding workarounds. “I don’t think anyone is panicking at the large AI companies,” says Pablo Villalobos, a Madrid-based researcher at Epoch AI and lead author of the study forecasting a 2028 data crash. “Or at least they don’t e-mail me if they are.”
For example, prominent AI companies such as OpenAI and Anthropic, both in San Francisco, California, have publicly acknowledged the issue while suggesting that they have plans to work around it, including generating new data and finding unconventional data sources. A spokesperson for OpenAI, told Nature: “We use numerous sources, including publicly available data and partnerships for non-public data, synthetic data generation and data from AI trainers.”
Even so, the data crunch might force an upheaval in the types of generative AI model that people build, possibly shifting the landscape away from big, all-purpose LLMs to smaller, more specialized models.
Trillions of words
LLM development over the past decade has shown its voracious appetite for data. Although some developers don’t publish the specifications of their latest models, Villalobos estimates that the number of ‘tokens’, or parts of words, used to train LLMs has risen 100-fold since 2020, from hundreds of billions to tens of trillions.

In AI, is bigger always better?
That could be a good chunk of what’s on the Internet, although the grand total is so vast that it’s hard to pin down — Villalobos estimates the total Internet stock of text data today at 3,100 trillion tokens. Various services use web crawlers to scrape this content, then eliminate duplications and filter out undesirable content (such as pornography) to produce cleaner data sets: a common one called RedPajama contains tens of trillions of words. Some companies or academics do the crawling and cleaning themselves to make bespoke data sets to train LLMs. A small proportion of the Internet is considered to be of high quality, such as human-edited, socially acceptable text that might be found in books or journalism.
The rate at which usable Internet content is increasing is surprisingly slow: Villalobos’s paper estimates that it is growing at less than 10% per year, while the size of AI training data sets is more than doubling annually. Projecting these trends shows the lines converging around 2028.
At the same time, content providers are increasingly including software code or refining their terms of use to block web crawlers or AI companies from scraping their data for training. Longpre and his colleagues released a preprint this July showing a sharp increase in how many data providers block specific crawlers from accessing their websites2. In the highest-quality, most-often-used web content across three main cleaned data sets, the number of tokens restricted from crawlers rose from less than 3% in 2023 to 20–33% in 2024.
Several lawsuits are now under way attempting to win compensation for the providers of data being used in AI training. In December 2023, The New York Times sued OpenAI and its partner Microsoft for copyright infringement; in April this year, eight newspapers owned by Alden Global Capital in New York City jointly filed a similar lawsuit. The counterargument is that an AI should be allowed to read and learn from online content in the same way as a person, and that this constitutes fair use of the material. OpenAI has said publicly that it thinks The New York Times lawsuit is “without merit”.
If courts uphold the idea that content providers deserve financial compensation, it will make it harder for both AI developers and researchers to get what they need — including academics, who don’t have deep pockets. “Academics will be most hit by these deals,” says Longpre. “There are many, very pro-social, pro-democratic benefits of having an open web,” he adds.
Finding data
[ad_2]
Source link
Leave a Reply